Kaip sukurti socialinės žiniasklaidos sentimentų analizės vamzdyną
Socialinės žiniasklaidos nuotaikų analizė gali būti labai naudinga stebint savo prekės ženklą, konkurentus ar bet kurią kitą dominančią temą. Šiame straipsnyje parodysime, kaip sukurti sistemą, kuri klausytųsi socialinės žiniasklaidos, pavyzdžiui, "Reddit", "Hacker News", "Linkedin", "Twitter" ir kt., ir automatiškai atliktų turinio nuotaikų analizę naudodama generatyvinį dirbtinį intelektą.
Socialinės klausymosi analizės derinimas su sentimentų analize siekiant atlikti prekės ženklo sentimentų analizę
Socialinis klausymasis - tai dėmesio atkreipimas į pokalbius tam tikromis temomis socialinės žiniasklaidos platformose, apžvalgų svetainėse ir kituose interneto kanaluose ir jų interpretavimas.
Kita vertus, nuotaikų analizė - tai procesas, kurio metu nustatomos ir kategorizuojamos tekste išreikštos nuomonės kaip teigiamos, neigiamos ar neutralios. Ji apima natūralios kalbos apdorojimo, teksto analizės ir kompiuterinės lingvistikos taikymą, siekiant sistemingai nustatyti, išskirti, kiekybiškai įvertinti ir ištirti afektines būsenas ir subjektyvią informaciją.
Sujungę klausymąsi socialiniuose tinkluose ir nuotaikų analizę, galite stebėti ir analizuoti nuotaikas, išreikštas pokalbiuose, susijusiuose su jūsų prekės ženklu arba konkurentais. Tai dar vadinama prekės ženklo nuotaikų analize. Prekės ženklo nuotaikų analizė leidžia automatiškai suprasti, ką vartotojai mano apie jūsų prekės ženklą ar konkurentus, nustatyti tobulintinas sritis, įsitraukti į reikiamą pokalbį socialinėje žiniasklaidoje ir užmegzti ryšį su potencialiais klientais bei priimti duomenimis pagrįstus sprendimus, kad padidintumėte savo prekės ženklo reputaciją ir klientų lojalumą.
Socialinės klausymosi platformos kūrimas
Norint sukurti socialinės klausymosi platformą, reikia prisijungti prie socialinės žiniasklaidos platformos ir gauti visus naujus įrašus ir komentarus, kuriuose yra norimų stebėti raktažodžių.
Tai lengviau padaryti, jei platforma, kurią planuojate stebėti, turi API. Pavyzdžiui, "Reddit" pateikia API, kurią galite lengvai naudoti. Pateikiame paprastą cURL užklausą, kuria gaunama 100 paskutinių "Reddit" įrašų:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
Kiekviena socialinės žiniasklaidos platforma turi savų subtilybių, kurių šiame straipsnyje, deja, negalime aptarti. Norėdami lengvai stebėti socialinės žiniasklaidos platformas (pavyzdžiui, "Reddit", "Linkedin", "X" ("Twitter"), "Hacker News" ir kt.), galite užsisakyti specialią socialinio klausymosi platformą, pavyzdžiui, mūsų paslaugą KWatch.io. Išbandykite KWatch.io nemokamai čia.
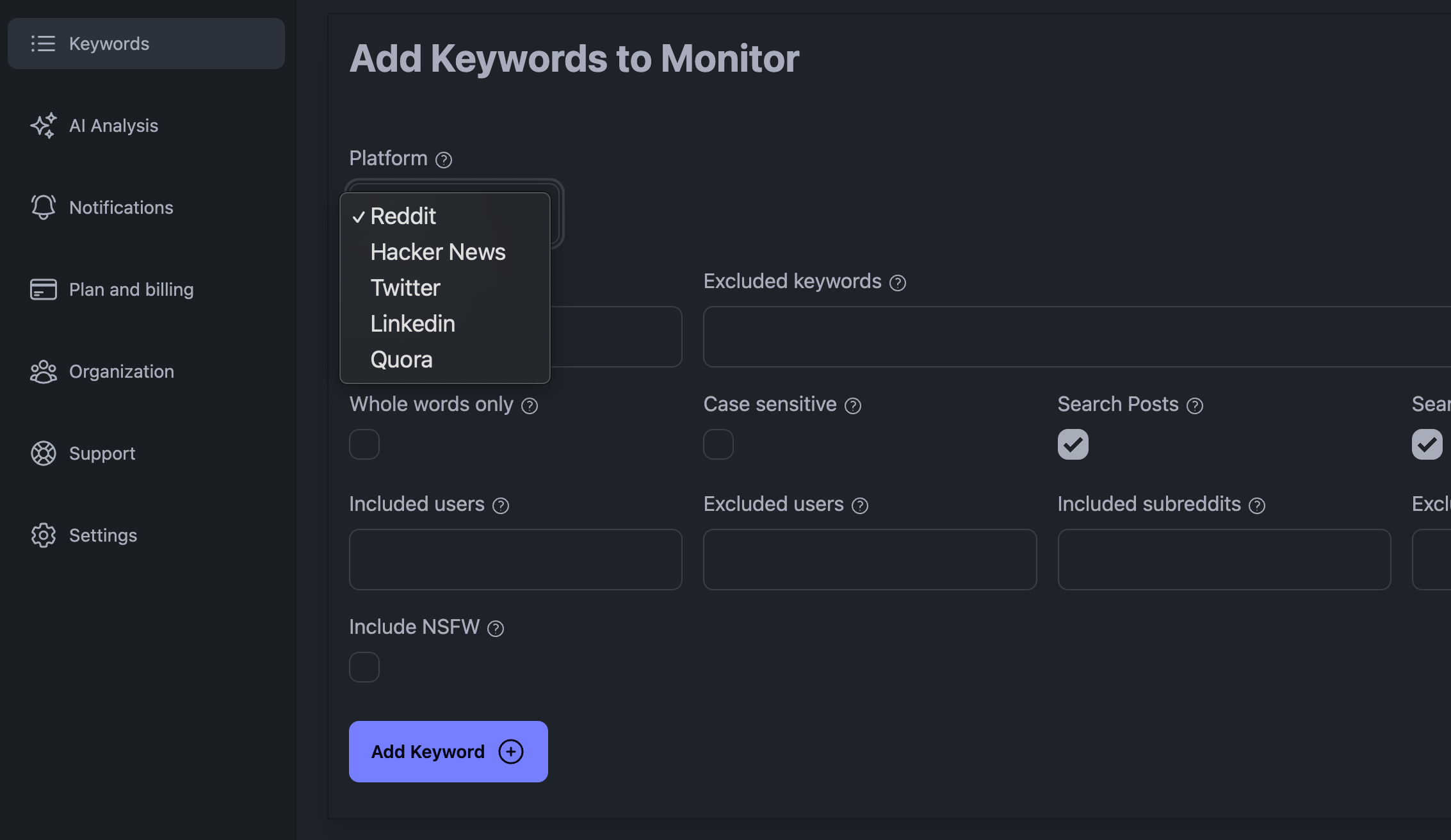
Pridėti raktinius žodžius į savo KWatch.io prietaisų skydelį
Kai kurie iš pagrindinių iššūkių, su kuriais susiduriama atliekant socialinės žiniasklaidos klausymąsi, yra dideli duomenų kiekiai, kuriuos reikia apdoroti, tai, kad socialinės žiniasklaidos platforma gali jus užblokuoti, jei pateiksite per daug užklausų, ir tai, kad turite protingai tvarkyti duomenis.
Kitame skyriuje paaiškinsime, kaip surinktus duomenis integruoti į sistemą.
Socialinės žiniasklaidos duomenų integravimas į sistemą
Surinkus duomenis iš socialinės žiniasklaidos platformų, juos reikia saugoti duomenų bazėje arba duomenų saugykloje. Taip galėsite analizuoti duomenis, atlikti nuotaikų analizę ir generuoti įžvalgas.
Socialinės žiniasklaidos duomenis (kurie iš esmės yra gryni tekstiniai duomenys) galima saugoti keliais būdais, priklausomai nuo jūsų reikalavimų ir apdorojamų duomenų kiekio. Keletas dažniausiai naudojamų variantų yra šie:
- reliacinės duomenų bazės, pavyzdžiui, "MySQL" arba "PostgreSQL", naudojimas
- NoSQL duomenų bazės, pavyzdžiui, "MongoDB" arba "Cassandra", naudojimas
- Naudojant duomenų saugyklą, pavyzdžiui, "Amazon Redshift" arba "Google BigQuery
Jei esate užsiprenumeravę socialinio klausymosi platformą, turėtumėte patikrinti, ar ji siūlo būdą perkelti duomenis į savo sistemą.
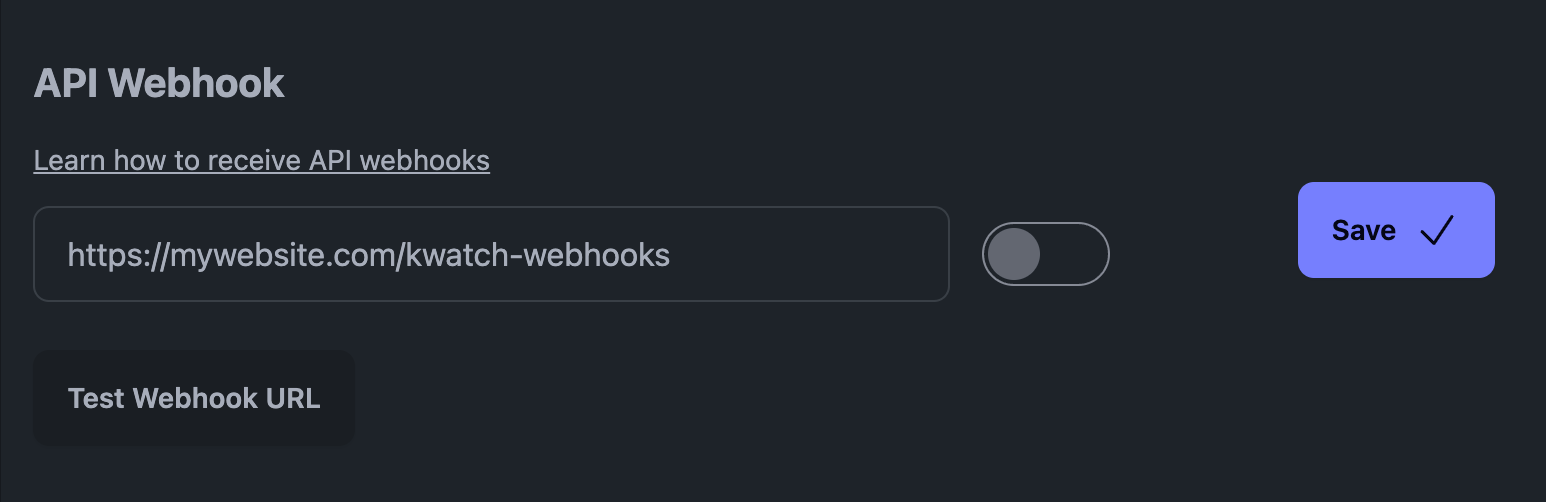
"Webhooks", dažnai vadinami "web callbacks" arba "HTTP push API", yra priemonė programoms dalytis duomenimis realiuoju laiku su kitomis programomis. Tai pasiekiama generuojant HTTP POST užklausas, kai įvyksta tam tikri įvykiai, ir tokiu būdu informacija greitai perduodama kitoms programoms.
Pavyzdžiui, mūsų platformoje KWatch.io turėtumėte eiti į skyrių "Pranešimai" ir nustatyti Webhook URL, nukreiptą į jūsų sistemą.
API Webhook KWatch.io
Štai kaip atrodo "KWatch.io" žiniatinklio kablys (tai JSON naudingoji apkrova):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Jei esate naujokas, galite be vargo gauti šiuos žiniatinklio kabliukus "Python" programoje naudodami FastAPI.
Įdiekite "FastAPI" su "Uvicorn" serveriu:
pip install fastapi uvicorn
Dabar sukurkite naują "Python" failą ir įklijuokite šį kodą (gali tekti šį scenarijų pritaikyti):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Išsaugokite failą ir paleiskite serverį šia komanda:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
Dabar jūsų serveris veikia ir yra paruoštas gauti "webhooks" iš "KWatch.io".
Duomenų sentimentų analizė naudojant generatyvinius dirbtinio intelekto modelius, tokius kaip GPT-4 arba LLaMA 3
Surinkę ir išsaugoję socialinės žiniasklaidos duomenis, galite atlikti jų nuotaikų analizę.
Šiandien tiksliausias būdas atlikti teksto dalies nuotaikų analizę, susijusią su konkrečiu raktiniu žodžiu, yra naudoti generatyvinius dirbtinio intelekto modelius, tokius kaip GPT-4, LLaMA 3, ChatDolphin ir kt. Šie LLM nebūtinai yra greiti ir gali būti brangūs taikant mastą, tačiau jie garantuoja pažangiausius rezultatus. Jei reikia analizuoti labai didelius raktažodžių kiekius, galbūt norėsite sumažinti sąnaudas naudodami mažesnius modelius arba tiksliai suderinkite savo modelį.
Galite įdiegti savo dirbtinio intelekto modelį arba prisijungti prie dirbtinio intelekto API, pavyzdžiui, "OpenAI" arba "NLP Cloud". Šiame straipsnyje prijungsime NLP Cloud AI API.
Jūsų užklausa neturi būti pernelyg sudėtinga. Pavyzdžiui, čia pateikiamas "Reddit" komentaras apie "OpenAI":
Komentaras "Reddit" apie "OpenAI
Naudokime "ChatDolphin" modelį "NLP Cloud", kad išanalizuotume nuotaikas apie "OpenAI" šiame "Reddit" komentare. Pirmiausia įdiekite NLP Cloud Python klientą:
pip install nlpcloud
Dabar galite analizuoti "Reddit" komentaro nuotaikas naudodami šį "Python" kodą:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
Atsakymas bus toks:
Negative
Dabar užbaigsime ir parašysime galutinį kodą, kuris klausosi API webhook ir atlieka duomenų nuotaikų analizę:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Išvada
Kaip matote, naudojant šiuolaikinius generatyvinius dirbtinio intelekto modelius ir efektyvius socialinio klausymosi įrankius galima automatizuoti socialinės žiniasklaidos duomenų nuotaikų analizę. Šį metodą galima taikyti įvairiuose socialinės žiniasklaidos stebėsenos scenarijuose. Štai keletas idėjų:
- Prekės ženklo reputacijos stebėjimas
- Konkurento reputacijos stebėjimas
- Akcijų pasirinkimo sandorio nuotaikų stebėjimas
- nuotaikų, susijusių su tam tikra technologine tendencija, pavyzdžiui, dirbtiniu intelektu ar kriptovaliutomis, stebėjimas.
- ...
Tačiau tokios programos kūrimas gali būti sudėtingas. Pirmiausia dėl to, kad socialinę žiniasklaidą nėra taip paprasta stebėti, taip pat dėl to, kad generatyvinius dirbtinio intelekto modelius gali būti brangu naudoti dideliems duomenų kiekiams.
Jei nenorite patys kurti ir prižiūrėti tokios sistemos, rekomenduojame naudoti mūsų platformą KWatch.io, nes mes automatiškai stebime socialinę žiniasklaidą ir atliekame aptiktų pranešimų ir komentarų nuotaikų analizę: užsiregistruoti KWatch.io čia.
 KWatch.io
KWatch.io