소셜 미디어의 감성 분석은 브랜드, 경쟁사 또는 기타 관심 있는 주제를 모니터링하는 데 매우 유용할 수 있습니다. 이 문서에서는 Reddit, Hacker News, Linkedin, Twitter 등과 같은 소셜 미디어를 청취하고 생성 AI를 통해 콘텐츠에 대한 감성 분석을 자동으로 수행하는 시스템을 구축하는 방법을 설명합니다.
브랜드 감성 분석을 위한 소셜 리스닝과 감성 분석의 결합
소셜 리스닝은 소셜 미디어 플랫폼, 리뷰 사이트 및 기타 온라인 채널에서 어떤 종류의 주제에 관한 대화에 주의를 기울이고 해석하는 행위입니다.
반면에 감정 분석은 텍스트에 표현된 의견을 긍정, 부정 또는 중립으로 식별하고 분류하는 프로세스입니다. 자연어 처리, 텍스트 분석, 컴퓨터 언어학을 사용하여 감정 상태와 주관적인 정보를 체계적으로 식별, 추출, 정량화 및 연구합니다.
소셜 리스닝과 감성 분석을 결합하면 브랜드 또는 경쟁사와 관련된 대화에서 표현되는 감성을 추적하고 분석할 수 있습니다. 이를 "브랜드 감성 분석"이라고도 합니다. 브랜드 감성 분석을 통해 소비자가 브랜드 또는 경쟁사에 대해 어떻게 느끼는지 자동으로 파악하고, 개선이 필요한 부분을 파악하고, 소셜 미디어에서 적절한 대화에 뛰어들어 잠재 고객과 소통하고, 데이터에 기반한 의사 결정을 내려 브랜드 평판과 고객 충성도를 높일 수 있습니다.
소셜 리스닝 플랫폼 구축
소셜 리스닝 플랫폼을 만들려면 소셜 미디어 플랫폼에 연결하여 모니터링하려는 키워드가 포함된 모든 새 게시물과 댓글을 검색해야 합니다.
모니터링하려는 플랫폼이 API를 노출하는 경우 이를 더 쉽게 달성할 수 있습니다. 예를 들어, Reddit은 쉽게 사용할 수 있는 API를 노출합니다. 다음은 최근 100개의 Reddit 게시물을 검색하는 간단한 cURL 요청입니다:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
각 소셜 미디어 플랫폼에는 안타깝게도 이 글에서 다룰 수 없는 미묘한 차이점이 있습니다. 레드딧, 링크드인, X(트위터), 해커 뉴스 등 소셜 미디어 플랫폼을 쉽게 모니터링하려면 KWatch.io 서비스와 같은 전용 소셜 리스닝 플랫폼에 가입하는 것이 좋습니다. 여기에서 KWatch.io를 무료로 사용해 보세요.
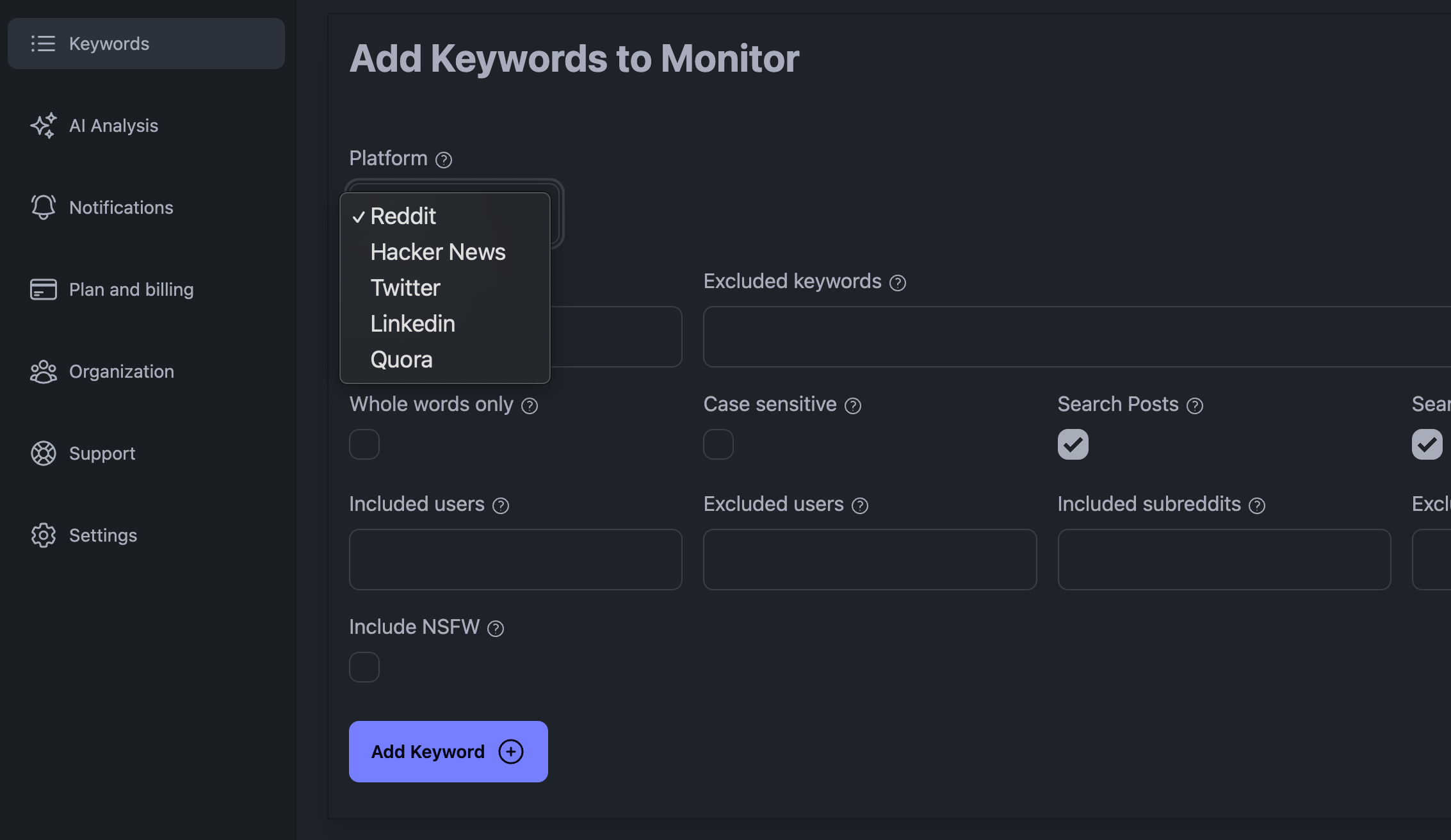
KWatch.io 대시보드에 키워드 추가하기
소셜 미디어 리스닝을 수행할 때 가장 큰 어려움은 처리해야 하는 데이터의 양이 많다는 점, 너무 많은 요청을 하면 소셜 미디어 플랫폼에서 차단될 수 있다는 점, 데이터를 처리하는 방식에 대해 현명하게 판단해야 한다는 점입니다.
다음 섹션에서는 수집된 데이터를 시스템에 통합하는 방법에 대해 설명합니다.
소셜 미디어 데이터를 시스템에 통합하기
소셜 미디어 플랫폼에서 데이터를 수집한 후에는 데이터베이스나 데이터 웨어하우스에 저장해야 합니다. 이를 통해 데이터를 분석하고, 감성 분석을 수행하고, 인사이트를 생성할 수 있습니다.
소셜 미디어 데이터(기본적으로 순수 텍스트 데이터)를 저장하는 방법에는 요구 사항과 처리하는 데이터의 양에 따라 여러 가지가 있습니다. 몇 가지 일반적인 옵션은 다음과 같습니다:
- MySQL 또는 PostgreSQL과 같은 관계형 데이터베이스 사용
- MongoDB 또는 Cassandra와 같은 NoSQL 데이터베이스 사용
- Amazon Redshift 또는 Google BigQuery와 같은 데이터 웨어하우스 사용
소셜 리스닝 플랫폼에 가입한 경우 해당 플랫폼에서 데이터를 시스템으로 전송할 수 있는 방법을 제공하는지 확인해야 합니다.
흔히 '웹 콜백' 또는 'HTTP 푸시 API'라고도 하는 웹훅은 애플리케이션이 다른 애플리케이션과 실시간 데이터를 공유하는 수단으로 사용됩니다. 이는 특정 이벤트가 발생할 때 HTTP POST 요청을 생성하여 다른 애플리케이션에 정보를 즉시 전달함으로써 이루어집니다.
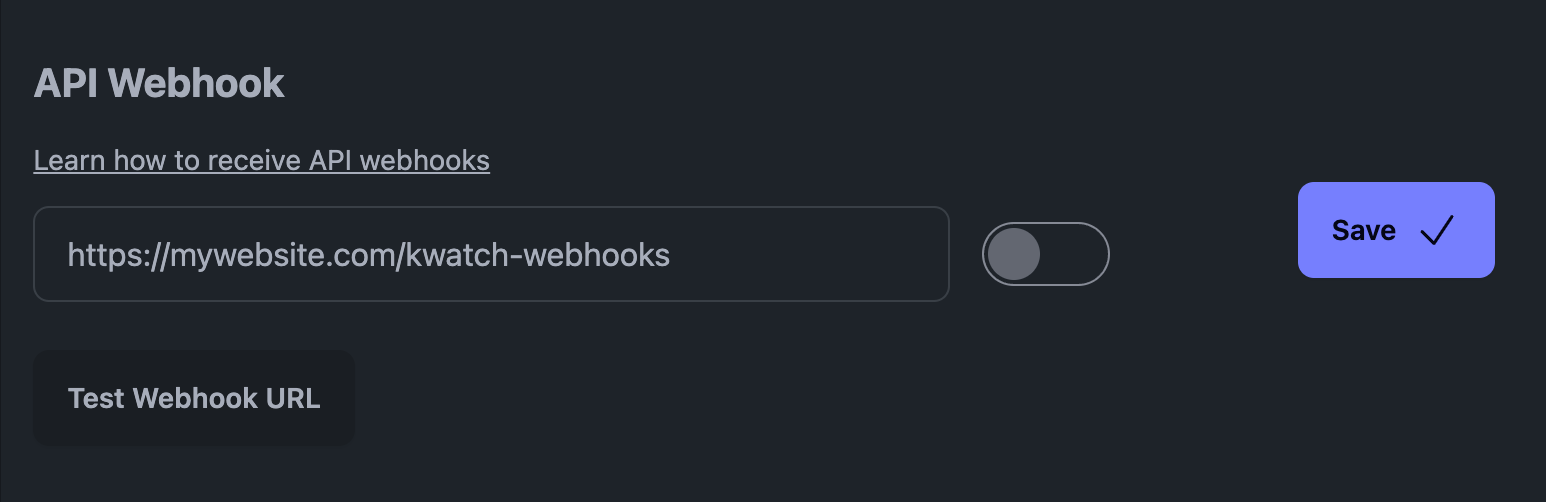
예를 들어 저희 플랫폼인 KWatch.io의 경우 '알림' 섹션으로 이동하여 시스템을 가리키는 웹훅 URL을 설정해야 합니다.
KWatch.io의 API 웹훅
다음은 KWatch.io 웹훅의 모습입니다(JSON 페이로드입니다):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
웹훅을 처음 사용하는 경우 FastAPI를 사용하여 Python에서 손쉽게 웹훅을 수신할 수 있습니다.
유비콘 서버에 FastAPI를 설치합니다:
pip install fastapi uvicorn
이제 새 Python 파일을 만들고 다음 코드를 붙여넣습니다(이 스크립트를 수정해야 할 수도 있습니다):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
파일을 저장하고 다음 명령어로 서버를 실행합니다:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
이제 서버가 실행 중이며 KWatch.io로부터 웹훅을 수신할 준비가 되었습니다.
GPT-4 또는 LLaMA 3과 같은 생성형 AI 모델을 사용하여 데이터에 대한 감정 분석 수행
소셜 미디어 데이터를 수집하고 저장한 후에는 소셜 미디어에 대한 감성 분석을 수행할 수 있습니다.
오늘날 특정 키워드에 대한 텍스트에 대한 감성 분석을 수행하는 가장 정확한 방법은 GPT-4, LLaMA 3, ChatDolphin 등과 같은 생성형 AI 모델을 사용하는 것입니다. 이러한 LLM은 반드시 빠르지는 않고 대규모로 비용이 많이 들 수 있지만, 최신의 결과를 보장합니다. 매우 많은 양의 키워드를 분석해야 하는 경우에는 더 작은 모델을 사용하여 비용을 낮추거나 자체 모델을 미세 조정할 수 있습니다.
자체 AI 모델을 배포하거나 OpenAI 또는 NLP Cloud와 같은 AI API에 연결할 수 있습니다. 이 문서에서는 NLP Cloud AI API에 연결하겠습니다.
요청이 너무 복잡할 필요는 없습니다. 예를 들어 다음은 Reddit에 올라온 OpenAI에 대한 댓글입니다:
OpenAI에 대한 Reddit의 댓글
이 Reddit 댓글의 OpenAI에 대한 감정을 분석하기 위해 NLP Cloud의 ChatDolphin 모델을 사용해 보겠습니다. 먼저 NLP Cloud Python 클라이언트를 설치합니다:
pip install nlpcloud
이제 다음 Python 코드를 사용하여 Reddit 댓글의 감성을 분석할 수 있습니다:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
응답은 다음과 같습니다:
Negative
이제 API 웹훅을 수신하고 데이터에 대한 감성 분석을 수행하는 최종 코드를 작성해 보겠습니다:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
결론
보시다시피, 최신 제너레이티브 AI 모델과 효율적인 소셜 리스닝 도구를 사용하면 소셜 미디어 데이터의 감성 분석을 자동화할 수 있습니다. 이 접근 방식은 다양한 소셜 미디어 모니터링 시나리오에 적용할 수 있습니다. 다음은 몇 가지 아이디어입니다:
- 브랜드 평판 추적
- 경쟁사의 평판 추적
- 스톡옵션을 둘러싼 정서를 주시하기
- AI 또는 암호화폐와 같은 특정 기술 트렌드와 관련된 감정 모니터링
- ...
하지만 이러한 프로그램을 제작하는 것은 어려울 수 있습니다. 소셜 미디어를 모니터링하기가 쉽지 않을 뿐만 아니라 생성형 AI 모델을 대용량 데이터에 사용하는 데 비용이 많이 들 수 있기 때문입니다.
이러한 시스템을 직접 구축하고 유지 관리하고 싶지 않다면 소셜 미디어를 자동으로 모니터링하고 감지된 게시물과 댓글에 대한 감성 분석을 수행하는 KWatch.io 플랫폼을 대신 사용하는 것이 좋습니다: 여기에서 KWatch.io에 등록하세요.
 KWatch.io
KWatch.io