ソーシャルメディア上のセンチメント分析は、自社ブランドや競合他社、その他関心のあるトピックをモニターするのに非常に役立つ。この記事では、Reddit、Hacker News、Linkedin、Twitterなどのソーシャルメディアに耳を傾け、生成AIのおかげで自動的にコンテンツのセンチメント分析を実行するシステムを構築する方法を紹介します。

ソーシャルリスニングとセンチメント分析の組み合わせによるブランドのセンチメント分析
ソーシャルリスニングとは、ソーシャルメディアプラットフォーム、レビューサイト、その他のオンラインチャンネル上のあらゆる種類のトピックに関する会話に注意を払い、解釈する行為である。
一方、センチメント分析とは、テキストに表現された意見を識別し、肯定的、否定的、または中立的に分類するプロセスである。自然言語処理、テキスト分析、計算言語学を用いて、感情状態や主観的な情報を体系的に識別、抽出、定量化、研究する。
ソーシャルリスニングとセンチメント分析を組み合わせると、自社ブランドや競合他社に関連する会話で表明されたセンチメントを追跡・分析することができます。これは「ブランドセンチメント分析」とも呼ばれます。ブランドセンチメント分析により、消費者が貴社ブランドや競合他社についてどのように感じているかを自動的に理解し、改善すべき点を特定し、ソーシャルメディア上の適切な会話に飛び込んで潜在顧客と関わり、データ駆動型の意思決定を行ってブランドの評判と顧客ロイヤルティを高めることができます。
ソーシャルリスニング・プラットフォームの構築
ソーシャルリスニングプラットフォームを作成するには、ソーシャルメディアプラットフォームに接続し、監視したいキーワードを含むすべての新しい投稿やコメントを取得する必要があります。
これは、監視しようとしているプラットフォームがAPIを公開していれば、より簡単に実現できる。例えば、Redditは簡単に利用できるAPIを公開している。以下は、Redditの直近100件の投稿を取得するシンプルなcURLリクエストです:
curl https://www.reddit.com/r/all/new/.json?limit=100
そして、これがAPIから返される典型的なレスポンスである:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
簡単なGoプログラムでRedditを監視する方法を紹介する専用のチュートリアルを作りました。 GoでRedditを監視する方法については、こちらをお読みください。
各ソーシャルメディア・プラットフォームにはそれぞれ微妙な違いがあり、残念ながらこの記事ではカバーしきれません。ソーシャルメディアプラットフォーム(Reddit、Linkedin、X(Twitter)、Hacker Newsなど)を簡単にモニターするには、私たちのKWatch.ioサービスのような専用のソーシャルリスニングプラットフォームに加入することをお勧めします。 KWatch.ioを無料でお試しください。
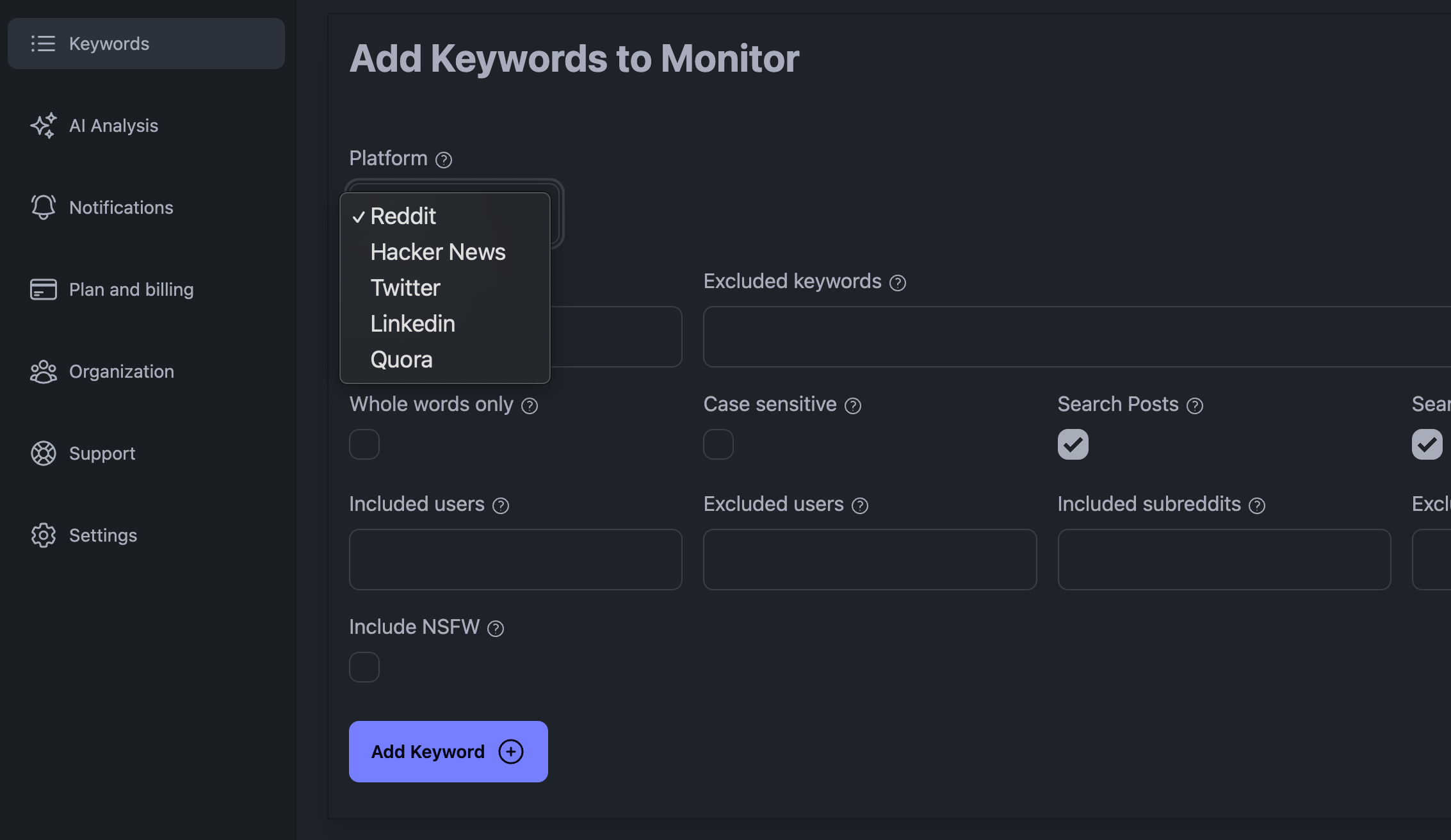 KWatch.ioダッシュボードにキーワードを追加する
KWatch.ioダッシュボードにキーワードを追加する
ソーシャルメディアリスニングを行う際の主な課題としては、扱わなければならないデータの量が多いこと、リクエストが多すぎるとソーシャルメディアプラットフォームにブロックされる可能性があること、データの扱い方について賢くなければならないことなどが挙げられる。
次のセクションでは、収集したデータをシステムに統合する方法を説明する。
ソーシャルメディアデータをシステムに統合する
ソーシャルメディア・プラットフォームからデータを収集したら、それをデータベースやデータウェアハウスに保存する必要がある。これにより、データを分析し、センチメント分析を実行し、洞察を生み出すことができるようになる。
ソーシャルメディアデータ(基本的には純粋なテキストデータ)を保存するには、要件や扱うデータ量に応じていくつかの方法があります。一般的な方法としては、以下のようなものがある:
-
- MySQLやPostgreSQLのようなリレーショナル・データベースの使用
-
- MongoDBやCassandraのようなNoSQLデータベースの使用
-
- Amazon RedshiftやGoogle BigQueryのようなデータウェアハウスを使う
ソーシャルリスニングプラットフォームを購読している場合、データをシステムに転送する方法を提供しているかどうかを確認する必要があります。
Webhookは、しばしば「Webコールバック」または「HTTPプッシュAPI」と呼ばれ、アプリケーションが他のアプリケーションとリアルタイムのデータを共有する手段として機能する。これは、特定のイベントが発生したときにHTTP POSTリクエストを生成し、他のアプリケーションに情報を迅速に配信することで実現される。
例えば、私たちのプラットフォームであるKWatch.ioでは、「notifications」セクションに行き、あなたのシステムを指すウェブフックURLを設定する必要があります。
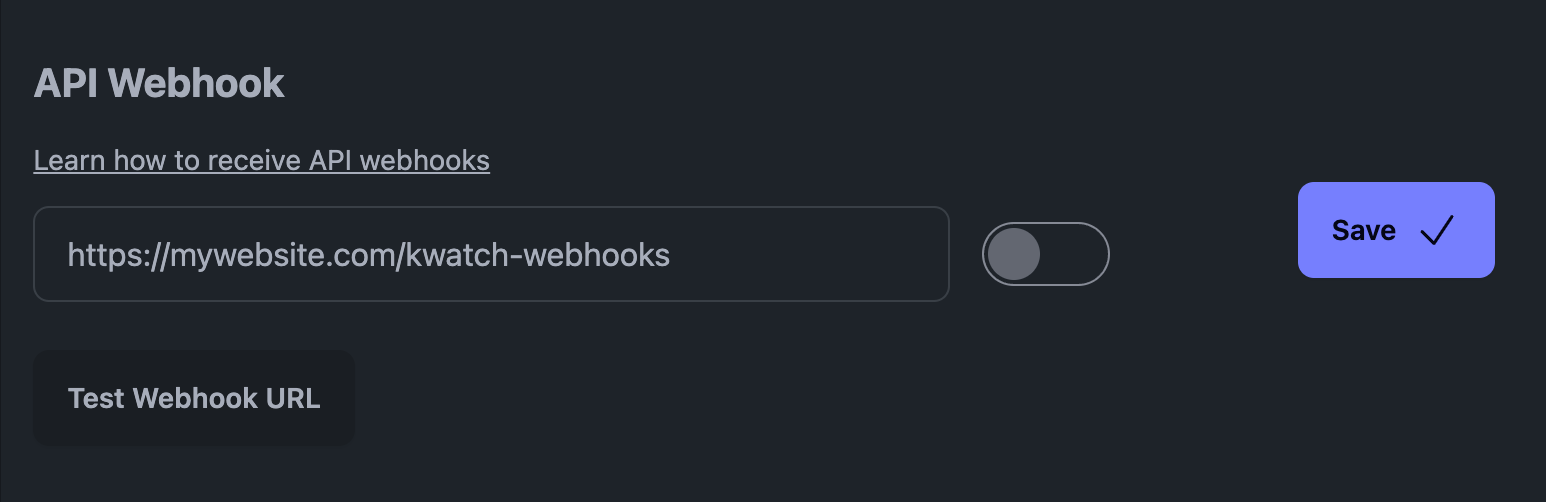 KWatch.ioのAPIウェブフック
KWatch.ioのAPIウェブフック
KWatch.ioのウェブフックはこんな感じです(JSONペイロードです):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
初めての方は、FastAPIを使ってPythonでこれらのWebhookを簡単に受け取ることができます。
Uvicorn サーバーに FastAPI をインストールします:
pip install fastapi uvicorn
新しいPythonファイルを作成し、以下のコードを貼り付ける(このスクリプトをアレンジする必要があるかもしれない):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
ファイルを保存し、以下のコマンドでサーバーを実行する:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
これであなたのサーバーは稼働し、KWatch.ioからWebhookを受信する準備が整いました。
GPT-4やLLaMA 3のような生成AIモデルによるデータのセンチメント分析
ソーシャルメディア・データを収集・保存したら、それに対してセンチメント分析を行うことができる。
今日、特定のキーワードに関するテキストに対してセンチメント分析を行う最も正確な方法は、GPT-4、LLaMA 3、ChatDolphinなどのような生成AIモデルを使用することです。これらのLLMは必ずしも高速ではなく、規模が大きくなるとコストがかかりますが、最先端の結果を保証します。非常に大量のキーワードを分析する必要がある場合は、より小さなモデルを使用することでコストを下げるか、独自のモデルを微調整することをお勧めします。
独自のAIモデルをデプロイすることもできるし、OpenAIやNLP CloudのようなAI APIにプラグインすることもできる。この記事では、NLP Cloud AI APIにプラグインすることにする。
こちらからNLPクラウドに登録し、APIキーを取得できます。
リクエストは複雑である必要はありません。例えば、OpenAIに関するRedditのコメントです:
 RedditでのOpenAIについてのコメント
RedditでのOpenAIについてのコメント
NLPクラウド上のChatDolphinモデルを使って、このRedditのコメントからOpenAIに関する感情を分析してみましょう。まず、NLP Cloud Pythonクライアントをインストールします:
pip install nlpcloud
次のPythonコードで、Redditコメントのセンチメントを分析できる:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
と答えるだろう:
Negative
それでは、APIウェブフックをリッスンし、データに対してセンチメント分析を実行する最終コードを書いて、まとめましょう:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
結論
最新の生成AIモデルと効率的なソーシャルリスニングツールの助けを借りて、ソーシャルメディアデータのセンチメント分析を自動化することが可能であることがお分かりいただけるでしょう。このアプローチは、様々なソーシャルメディアモニタリングシナリオに適用できる。ここにいくつかのアイデアがある:
-
- ブランド評価の追跡
-
- 競合他社の評判を追跡
-
- ストックオプションを取り巻くセンチメントを注視する
-
- AIや暗号など、特定の技術トレンドに関連するセンチメントをモニタリングする。
-
- ...
しかし、このようなプログラムを作成するのは難しい。第一に、ソーシャルメディアの監視はそれほど容易ではないからであり、また、生成AIモデルを大量のデータに使用するにはコストがかかるからである。
このようなシステムをご自身で構築・維持したくない場合は、代わりに当社のKWatch.ioプラットフォームを使用することをお勧めします。当社はソーシャルメディアを自動的に監視し、検出された投稿やコメントに対してセンチメント分析を行います: KWatch.ioへの登録はこちらから。
Arthur
KWatch.ioのCTO
 KWatch.io
KWatch.io