Как построить конвейер для анализа настроения в социальных сетях
Анализ настроений в социальных сетях может быть очень полезен для мониторинга вашего бренда, ваших конкурентов или любой другой интересующей вас темы. В этой статье мы покажем вам, как построить систему, которая слушает социальные сети, такие как Reddit, Hacker News, Linkedin, Twitter и т. д., и автоматически выполняет анализ настроений в контенте благодаря генеративному ИИ.
Сочетание социального прослушивания с анализом настроения для анализа настроения бренда
Социальное прослушивание - это процесс изучения и интерпретации разговоров на любые темы в социальных сетях, на сайтах отзывов и других онлайн-каналах.
С другой стороны, анализ настроения - это процесс выявления и классификации мнений, выраженных в тексте, как положительных, отрицательных или нейтральных. Он предполагает использование обработки естественного языка, анализа текста и вычислительной лингвистики для систематической идентификации, извлечения, количественной оценки и изучения аффективных состояний и субъективной информации.
Если объединить социальное прослушивание и анализ настроений, можно отслеживать и анализировать настроения, выраженные в разговорах, связанных с вашим брендом или вашими конкурентами. Это также известно как "анализ настроений бренда". Анализ настроений бренда позволяет автоматически понять, как потребители относятся к вашему бренду или вашим конкурентам, выявить области, требующие улучшения, вступить в нужный разговор в социальных сетях, чтобы привлечь потенциальных клиентов, и принять решения, основанные на данных, для повышения репутации вашего бренда и лояльности клиентов.
Создание платформы социальной прослушки
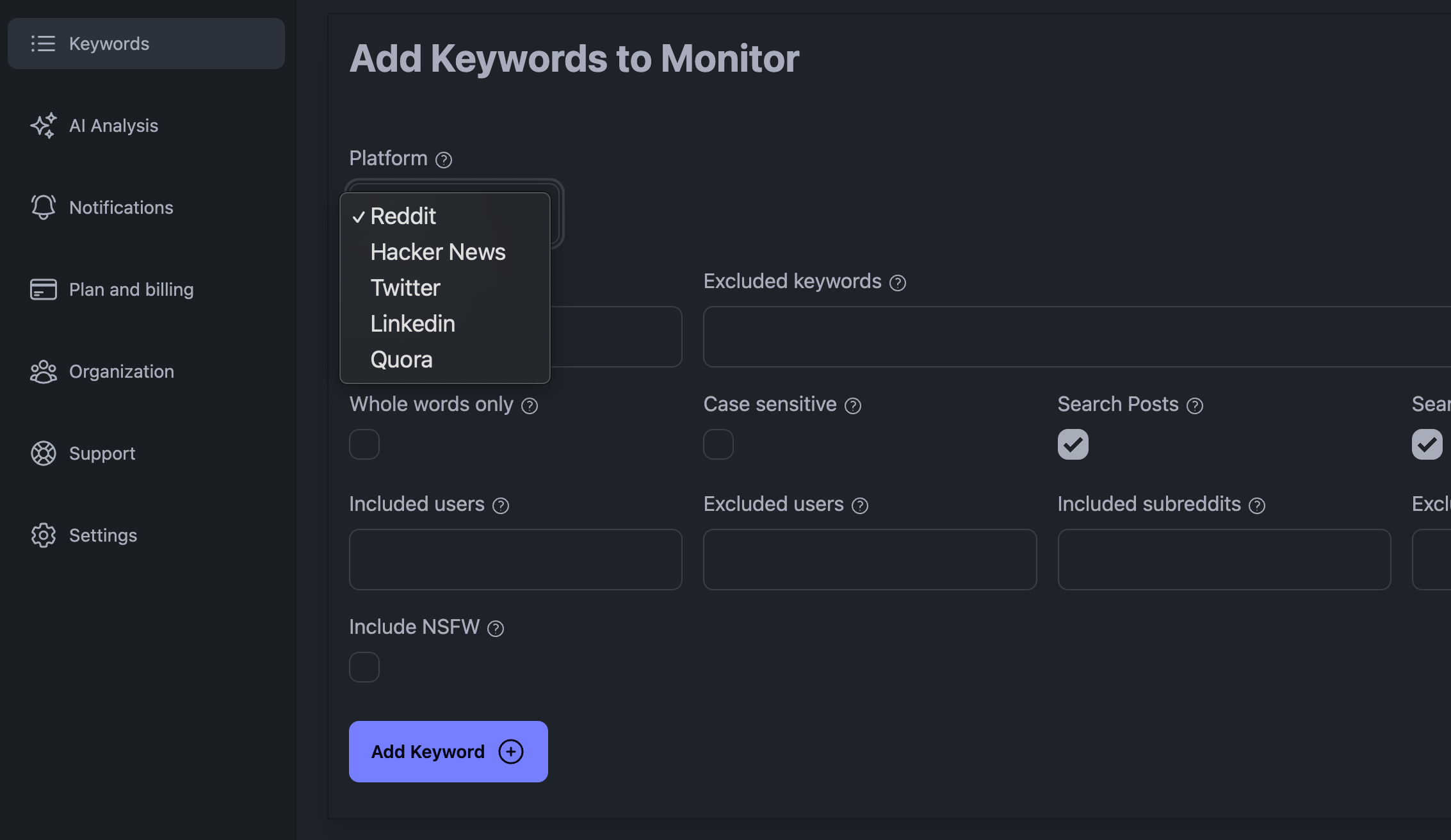
Для создания платформы социального прослушивания необходимо подключиться к платформе социальных сетей и получать все новые сообщения и комментарии, содержащие ключевые слова, которые вы хотите отслеживать.
Этого легче добиться, если платформа, которую вы планируете отслеживать, предоставляет API. Например, Reddit предоставляет API, который вы можете легко использовать. Вот простой запрос cURL, который извлекает последние 100 сообщений Reddit:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
У каждой платформы социальных сетей есть свои тонкости, которые мы, к сожалению, не можем описать в этой статье. Чтобы легко отслеживать социальные медиаплатформы (такие как Reddit, Linkedin, X, Hacker News и другие), вам стоит подписаться на специализированную платформу социального прослушивания, например, на наш сервис KWatch.io. Попробуйте KWatch.io бесплатно здесь.
Добавьте ключевые слова в приборную панель KWatch.io
Среди основных проблем, возникающих при прослушивании социальных сетей, - большой объем данных, с которыми приходится работать, тот факт, что платформа социальной сети может заблокировать вас, если вы сделаете слишком много запросов, а также то, что вы должны с умом подходить к обработке данных.
В следующем разделе мы расскажем, как интегрировать собранные данные в вашу систему.
Интеграция данных из социальных сетей в вашу систему
Собрав данные с платформ социальных сетей, необходимо сохранить их в базе данных или хранилище данных. Это позволит вам анализировать данные, проводить анализ настроений и генерировать выводы.
Существует несколько способов хранения данных социальных сетей (которые, по сути, являются чисто текстовыми данными), в зависимости от ваших требований и объема данных, с которыми вы имеете дело. Некоторые распространенные варианты включают:
- Использование реляционной базы данных, например MySQL или PostgreSQL
- Использование базы данных NoSQL, например MongoDB или Cassandra
- Использование хранилища данных, например Amazon Redshift или Google BigQuery
Если вы подписались на платформу социального прослушивания, проверьте, есть ли у нее возможность передавать данные в вашу систему.
Webhooks, часто называемые "обратными веб-вызовами" или "HTTP push API", служат для обмена данными в реальном времени с другими приложениями. Это достигается путем генерации HTTP POST-запросов при наступлении определенных событий, что позволяет оперативно доставлять информацию другим приложениям.
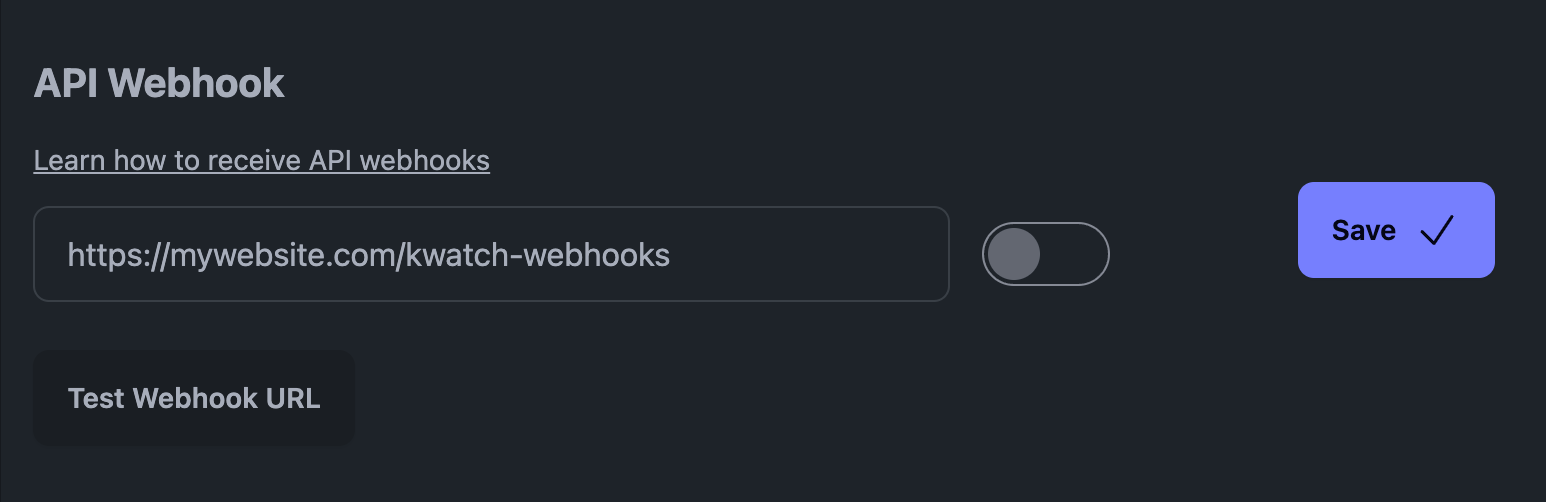
Например, на нашей платформе, KWatch.io, вам нужно перейти в раздел "Уведомления" и установить URL-адрес веб-хука, указывающий на вашу систему.
API Webhook на KWatch.io
Вот как выглядит вебхук KWatch.io (это полезная нагрузка в формате JSON):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Если вы новичок в этом деле, вы можете легко получать эти веб-крючки в Python с помощью FastAPI.
Установите FastAPI с сервером Uvicorn:
pip install fastapi uvicorn
Теперь создайте новый файл Python и вставьте в него следующий код (возможно, вам придется адаптировать этот сценарий):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Сохраните файл и запустите сервер с помощью следующей команды:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
Теперь ваш сервер запущен и готов получать веб-крючки от KWatch.io.
Проведение анализа настроений на основе данных с помощью генеративных моделей ИИ, таких как GPT-4 или LLaMA 3
Собрав и сохранив данные из социальных сетей, вы можете провести анализ их настроения.
Сегодня самый точный способ провести анализ настроения в тексте по определенному ключевому слову - это использование генеративных моделей ИИ, таких как GPT-4, LLaMA 3, ChatDolphin и т. д. Эти модели не обязательно быстрые и могут быть дорогостоящими в масштабе, но они гарантируют получение самых современных результатов. Если вам нужно анализировать очень большие объемы ключевых слов, вы можете снизить затраты за счет использования более мелких моделей или доработать собственную модель.
Вы можете развернуть свою собственную модель ИИ или подключиться к API ИИ, например OpenAI или NLP Cloud. В этой статье мы подключимся к NLP Cloud AI API.
Ваш запрос не обязательно должен быть слишком сложным. Вот, например, комментарий на Reddit, посвященный OpenAI:
Комментарий на Reddit об OpenAI
Давайте воспользуемся моделью ChatDolphin на NLP Cloud, чтобы проанализировать настроения по поводу OpenAI в этом комментарии на Reddit. Сначала установите Python-клиент NLP Cloud:
pip install nlpcloud
Теперь вы можете проанализировать настроение комментария на Reddit с помощью следующего кода на Python:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
Ответ будет таким:
Negative
Теперь давайте завершим работу и напишем финальный код, который прослушивает вебхук API и выполняет анализ настроения данных:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Заключение
Как видите, с помощью современных генеративных моделей ИИ и эффективных инструментов социального прослушивания можно автоматизировать анализ настроений в данных социальных медиа. Этот подход можно применять в различных сценариях мониторинга социальных сетей. Вот несколько идей:
- Отслеживание репутации вашего бренда
- Отслеживание репутации конкурентов
- Следите за настроениями вокруг опционов на акции
- Мониторинг настроений, связанных с определенным технологическим трендом, таким как ИИ или криптовалюты
- ...
Однако создание такой программы может оказаться непростой задачей. Во-первых, потому что социальные сети не так просто контролировать, а во-вторых, потому что генеративные модели ИИ могут быть дорогостоящими при использовании больших объемов данных.
Если вы не хотите самостоятельно создавать и поддерживать такую систему, мы рекомендуем вам использовать нашу платформу KWatch.io, поскольку мы автоматически отслеживаем социальные сети и проводим анализ настроения обнаруженных постов и комментариев: зарегистрируйтесь на сайте KWatch.io здесь.
 KWatch.io
KWatch.io