Slik bygger du opp en pipeline for sentimentanalyse i sosiale medier
Sentimentanalyse på sosiale medier kan være svært nyttig for å overvåke merkevaren din, konkurrentene dine eller andre emner av interesse. I denne artikkelen viser vi deg hvordan du kan bygge et system som lytter til sosiale medier som Reddit, Hacker News, Linkedin, Twitter osv. og automatisk utfører sentimentanalyse på innholdet takket være generativ AI.
Kombinere sosial lytting med sentimentanalyse for å analysere sentimenter knyttet til merkevarer
Sosial lytting handler om å følge med på og tolke samtaler om et hvilket som helst tema på sosiale medier, anmeldelsessider og andre nettbaserte kanaler.
Sentimentanalyse, på den annen side, er prosessen med å identifisere og kategorisere meninger uttrykt i en tekst som positive, negative eller nøytrale. Det innebærer å bruke naturlig språkbehandling, tekstanalyse og datalingvistikk til systematisk å identifisere, trekke ut, kvantifisere og studere affektive tilstander og subjektiv informasjon.
Når du kombinerer sosial lytting og sentimentanalyse, kan du spore og analysere sentimentet som kommer til uttrykk i samtaler knyttet til merkevaren din eller konkurrentene dine. Dette er også kjent som "sentimentanalyse". Med sentimentanalyse kan du automatisk forstå hva forbrukerne mener om merkevaren din eller konkurrentene dine, identifisere forbedringsområder, hoppe inn i den rette samtalen på sosiale medier for å komme i dialog med potensielle kunder, og ta datadrevne beslutninger for å forbedre merkevarens omdømme og kundelojalitet.
Bygge en plattform for sosial lytting
For å lage en plattform for sosial lytting må du koble deg til en sosial medieplattform og hente inn alle nye innlegg og kommentarer som inneholder nøkkelordene du vil overvåke.
Dette er lettere å få til hvis plattformen du planlegger å overvåke, har et API. Reddit har for eksempel et API som du enkelt kan bruke. Her er en enkel cURL-forespørsel som henter de siste 100 Reddit-innleggene:
Og her er et typisk svar som API-et deres returnerer:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
Hver sosiale medieplattform har sine egne finesser som vi dessverre ikke kan dekke i denne artikkelen. For å enkelt overvåke sosiale medieplattformer (som Reddit, Linkedin, X, Hacker News og flere), kan det være lurt å abonnere på en dedikert sosial lytteplattform som vår KWatch.io-tjeneste. Prøv KWatch.io gratis her.
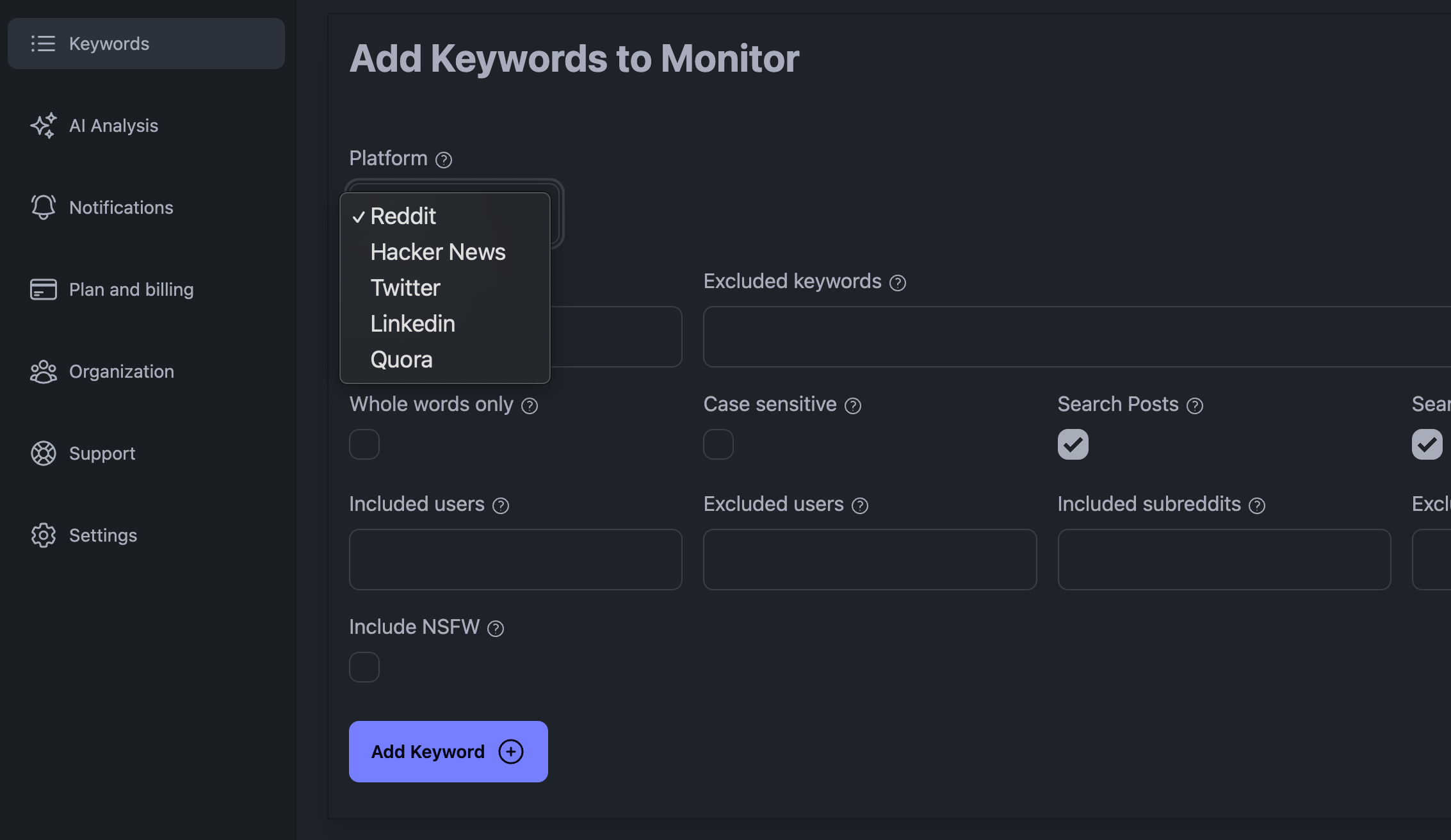
Legg til nøkkelord i KWatch.io-instrumentbordet
Noen av de største utfordringene ved å lytte til sosiale medier er den store datamengden du må håndtere, det faktum at du kan bli blokkert av den sosiale medieplattformen hvis du kommer med for mange forespørsler, og det faktum at du må være smart med tanke på hvordan du håndterer dataene.
I neste avsnitt forklarer vi hvordan du integrerer de innsamlede dataene i systemet ditt.
Integrering av data fra sosiale medier i systemet ditt
Når du har samlet inn data fra sosiale medier, må du lagre dem i en database eller et datavarehus. På den måten kan du analysere dataene, utføre sentimentanalyser og generere innsikt.
Det finnes flere måter å lagre data fra sosiale medier (som i utgangspunktet er rene tekstdata) på, avhengig av hvilke krav du har og hvor store datamengder du har å gjøre med. Noen vanlige alternativer inkluderer:
- Bruk av en relasjonsdatabase som MySQL eller PostgreSQL
- Bruk av en NoSQL-database som MongoDB eller Cassandra
- Bruk av et datalager som Amazon Redshift eller Google BigQuery
Hvis du abonnerer på en sosial lytteplattform, bør du sjekke om de tilbyr en måte å overføre dataene til systemet ditt på.
Webhooks, ofte omtalt som "web callbacks" eller "HTTP push API", gjør det mulig for applikasjoner å dele sanntidsdata med andre applikasjoner. Dette oppnås ved å generere HTTP POST-forespørsler når bestemte hendelser inntreffer, slik at andre applikasjoner får informasjon umiddelbart.
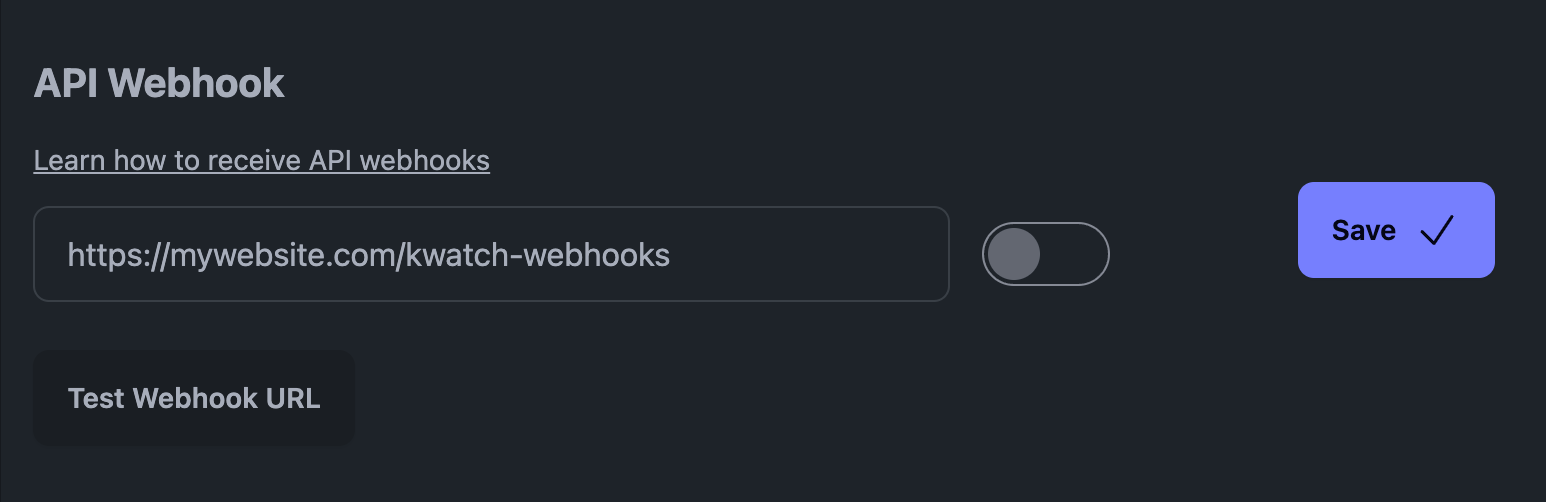
På vår plattform, KWatch.io, bør du for eksempel gå til "notifications"-delen og angi en webhook-URL som peker til systemet ditt.
API-webhook på KWatch.io
Slik ser KWatch.io webhook ut (det er en JSON-nyttelast):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Hvis dette er nytt for deg, kan du enkelt motta disse webhooksene i Python ved hjelp av FastAPI.
Installer FastAPI med Uvicorn-serveren:
pip install fastapi uvicorn
Opprett nå en ny Python-fil og lim inn følgende kode (det kan hende du må tilpasse dette skriptet):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Lagre filen, og kjør serveren med følgende kommando:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
Serveren din er nå i drift og klar til å motta webhooks fra KWatch.io.
Sentimentanalyse av data med generative AI-modeller som GPT-4 eller LLaMA 3
Når du har samlet inn og lagret dataene fra sosiale medier, kan du utføre sentimentanalyse på dem.
I dag er den mest nøyaktige måten å utføre sentimentanalyse på et stykke tekst om et bestemt nøkkelord ved å bruke generative AI-modeller som GPT-4, LLaMA 3, ChatDolphin osv. Disse LLM-ene er ikke nødvendigvis raske og kan være kostbare i stor skala, men de garanterer toppmoderne resultater. Hvis du har behov for å analysere svært store mengder søkeord, kan det være lurt å redusere kostnadene ved å bruke mindre modeller, eller finjustere din egen modell.
Du kan distribuere din egen AI-modell, eller koble deg til et AI-API som OpenAI eller NLP Cloud. I denne artikkelen vil vi koble oss til NLP Cloud AI API.
Forespørselen din trenger ikke å være for kompleks. Her er for eksempel en kommentar på Reddit, om OpenAI:
En kommentar på Reddit om OpenAI
La oss bruke ChatDolphin-modellen på NLP Cloud for å analysere følelsen om OpenAI i denne Reddit-kommentaren. Først installerer du NLP Cloud Python-klienten:
pip install nlpcloud
Nå kan du analysere sentimentet i Reddit-kommentaren med følgende Python-kode:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
Svaret vil være:
Negative
Nå skal vi avslutte og skrive den endelige koden som lytter til API-webhooken og utfører sentimentanalyse på dataene:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Konklusjon
Som du kan se, er det mulig å automatisere sentimentanalyse av data fra sosiale medier ved hjelp av moderne generative AI-modeller og effektive verktøy for sosial lytting. Denne tilnærmingen kan brukes i ulike scenarier for overvåking av sosiale medier. Her er noen ideer:
- Følg med på omdømmet til merkevaren din
- Sporing av en konkurrents omdømme
- Følg med på stemningen rundt en aksjeopsjon
- Overvåke stemningen knyttet til en spesifikk teknologisk trend, for eksempel AI eller krypto
- ...
Det kan imidlertid være utfordrende å produsere et slikt program. For det første fordi sosiale medier ikke er så enkle å overvåke, men også fordi generative AI-modeller kan være kostbare å bruke på store datamengder.
Hvis du ikke ønsker å bygge og vedlikeholde et slikt system selv, anbefaler vi at du i stedet bruker KWatch.io-plattformen vår, ettersom vi automatisk overvåker sosiale medier og utfører sentimentanalyse på de oppdagede innleggene og kommentarene: registrer deg på KWatch.io her.
 KWatch.io
KWatch.io