Come costruire una pipeline di analisi del sentiment dei social media
L'analisi del sentiment sui social media può essere molto utile per monitorare il vostro marchio, i vostri concorrenti o qualsiasi altro argomento di interesse. In questo articolo vi mostriamo come costruire un sistema che ascolti i social media come Reddit, Hacker News, Linkedin, Twitter, ecc. ed esegua automaticamente la sentiment analysis sui contenuti grazie all'IA generativa.
Combinare l'ascolto sociale con l'analisi del sentimento per l'analisi del sentimento del marchio
L'ascolto sociale è l'atto di prestare attenzione e interpretare le conversazioni intorno a qualsiasi tipo di argomento sulle piattaforme dei social media, sui siti di recensioni e su altri canali online.
La sentiment analysis, invece, è il processo di identificazione e categorizzazione delle opinioni espresse in un testo come positive, negative o neutre. Si tratta di utilizzare l'elaborazione del linguaggio naturale, l'analisi del testo e la linguistica computazionale per identificare, estrarre, quantificare e studiare sistematicamente gli stati affettivi e le informazioni soggettive.
Quando si combinano l'ascolto sociale e l'analisi del sentiment, è possibile tracciare e analizzare il sentiment espresso nelle conversazioni relative al vostro marchio o ai vostri concorrenti. Questa operazione è nota anche come "brand sentiment analysis". L'analisi del sentiment del marchio vi permette di capire automaticamente come i consumatori pensano al vostro marchio o ai vostri concorrenti, di identificare le aree di miglioramento, di entrare nella giusta conversazione sui social media per coinvolgere i potenziali clienti e di prendere decisioni basate sui dati per migliorare la reputazione del vostro marchio e la sua fedeltà.
Creare una piattaforma di ascolto sociale
Per creare una piattaforma di social listening è necessario collegarsi a una piattaforma di social media e recuperare tutti i nuovi post e commenti che contengono le parole chiave che si desidera monitorare.
Ciò è più facile se la piattaforma che si intende monitorare espone un'API. Ad esempio, Reddit espone un'API che può essere facilmente utilizzata. Ecco una semplice richiesta cURL che recupera gli ultimi 100 post di Reddit:
Ecco una tipica risposta restituita dalla loro API:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
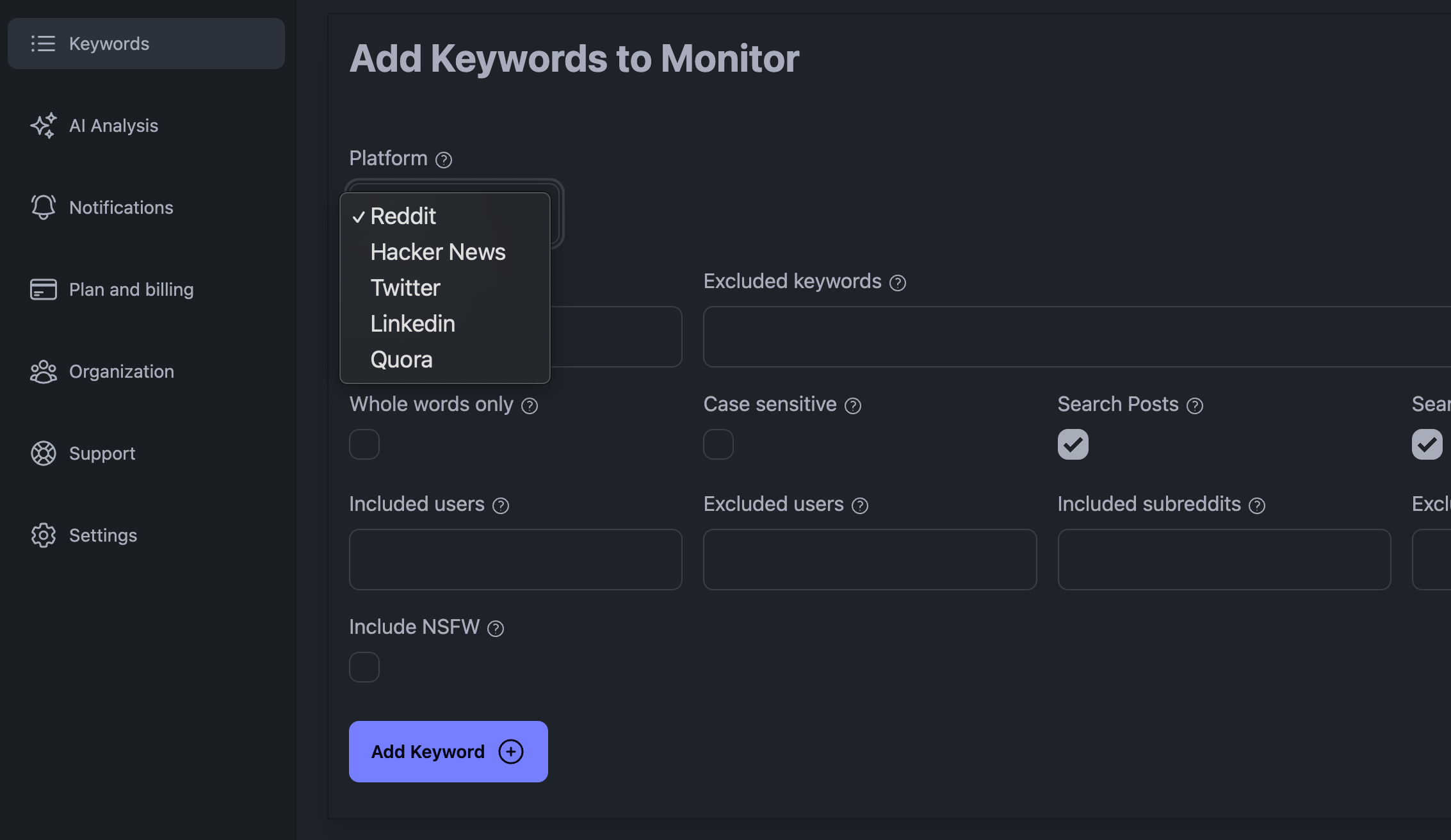
Ogni piattaforma di social media ha le sue sottigliezze che purtroppo non possiamo trattare in questo articolo. Per monitorare facilmente le piattaforme di social media (come Reddit, Linkedin, X, Hacker News e altre), potreste iscrivervi a una piattaforma di social listening dedicata, come il nostro servizio KWatch.io. Provate KWatch.io gratuitamente qui.
Aggiungi parole chiave nel tuo cruscotto KWatch.io
Alcune delle sfide principali, quando si esegue il social media listening, sono l'elevato volume di dati da gestire, il fatto che si può essere bloccati dalla piattaforma di social media se si fanno troppe richieste e il fatto che bisogna essere intelligenti nel gestire i dati.
Nella prossima sezione verrà spiegato come integrare i dati raccolti nel sistema.
Integrazione dei dati dei social media nel vostro sistema
Una volta raccolti i dati dalle piattaforme dei social media, è necessario archiviarli in un database o in un data warehouse. In questo modo sarà possibile analizzare i dati, eseguire la sentiment analysis e generare approfondimenti.
Esistono diversi modi per archiviare i dati dei social media (che sono fondamentalmente dati testuali puri), a seconda delle esigenze e del volume di dati da gestire. Alcune opzioni comuni sono:
- Utilizzo di un database relazionale come MySQL o PostgreSQL
- Utilizzo di un database NoSQL come MongoDB o Cassandra
- Utilizzo di un data warehouse come Amazon Redshift o Google BigQuery
Se vi siete iscritti a una piattaforma di social listening, dovreste verificare se offre un modo per trasferire i dati nel vostro sistema.
I webhook, spesso chiamati "web callback" o "HTTP push API", servono alle applicazioni per condividere dati in tempo reale con altre applicazioni. Ciò avviene generando richieste HTTP POST quando si verificano eventi specifici, in modo da fornire tempestivamente informazioni ad altre applicazioni.
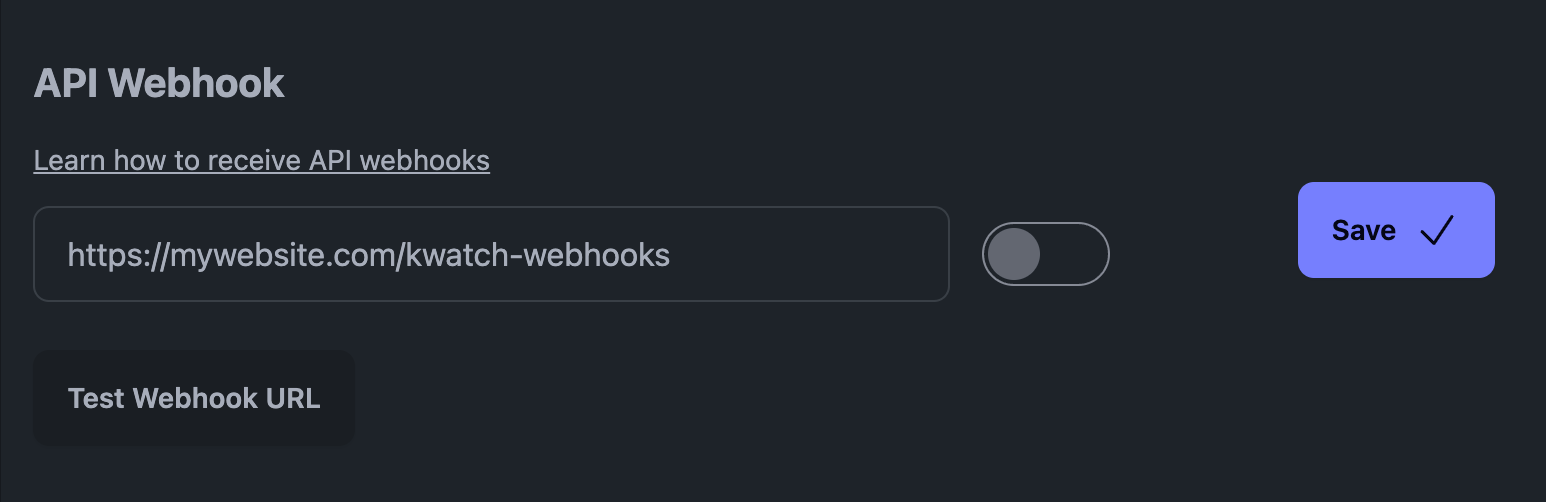
Ad esempio, sulla nostra piattaforma, KWatch.io, si deve andare nella sezione "notifiche" e impostare un URL webhook che punti al proprio sistema.
Webhook API su KWatch.io
Ecco come appare il webhook di KWatch.io (si tratta di un payload JSON):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Se siete alle prime armi, potete ricevere senza problemi questi webhook in Python usando FastAPI.
Installare FastAPI con il server Uvicorn:
pip install fastapi uvicorn
Ora create un nuovo file Python e incollate il seguente codice (potrebbe essere necessario adattare questo script):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Salvare il file ed eseguire il server con il seguente comando:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
Il vostro server è ora in funzione e pronto a ricevere webhook da KWatch.io.
Esecuzione dell'analisi del sentiment sui dati con modelli di intelligenza artificiale generativa come GPT-4 o LLaMA 3
Una volta raccolti e archiviati i dati dei social media, è possibile eseguire l'analisi del sentiment su di essi.
Oggi il modo più accurato per eseguire la sentiment analysis su un testo relativo a una specifica parola chiave è quello di utilizzare modelli generativi di intelligenza artificiale come GPT-4, LLaMA 3, ChatDolphin, ecc. Questi LLM non sono necessariamente veloci e possono essere costosi in scala, ma garantiscono risultati all'avanguardia. Se avete bisogno di analizzare volumi molto elevati di parole chiave, potreste voler ridurre i costi utilizzando modelli più piccoli o perfezionando il vostro modello.
È possibile distribuire il proprio modello di IA o collegarsi a un'API di IA come OpenAI o NLP Cloud. In questo articolo ci collegheremo all'API NLP Cloud AI.
La richiesta non deve essere troppo complessa. Ad esempio, ecco un commento su Reddit, a proposito di OpenAI:
Un commento su Reddit a proposito di OpenAI
Utilizziamo il modello ChatDolphin su NLP Cloud per analizzare il sentiment su OpenAI in questo commento su Reddit. Innanzitutto, installare il client Python di NLP Cloud:
pip install nlpcloud
Ora è possibile analizzare il sentiment dei commenti di Reddit con il seguente codice Python:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
La risposta sarà:
Negative
Ora concludiamo e scriviamo il codice finale che ascolta il webhook dell'API ed esegue la sentiment analysis sui dati:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Conclusione
Come si può vedere, è possibile automatizzare l'analisi del sentiment sui dati dei social media con l'aiuto di moderni modelli di intelligenza artificiale generativa e di efficienti strumenti di ascolto sociale. Questo approccio può essere applicato a diversi scenari di monitoraggio dei social media. Ecco alcune idee:
- Monitoraggio della reputazione del marchio
- Tracciare la reputazione di un concorrente
- Tenere d'occhio il sentiment relativo a un'opzione azionaria
- Monitoraggio del sentiment relativo a una specifica tendenza tecnologica, come l'IA o la criptovaluta.
- ...
La produzione di un programma di questo tipo può però essere impegnativa. Innanzitutto perché i social media non sono così facili da monitorare, ma anche perché i modelli di IA generativa possono essere costosi da usare su grandi volumi di dati.
Se non volete costruire e mantenere un sistema del genere da soli, vi consigliamo di utilizzare la nostra piattaforma KWatch.io, che monitora automaticamente i social media ed esegue un'analisi del sentiment sui post e sui commenti rilevati: registrarsi su KWatch.io qui.
 KWatch.io
KWatch.io