Kuidas ehitada sotsiaalmeedia tunnetusanalüüsi torujuhe
Sotsiaalmeedia tundemõõtmine võib olla väga kasulik teie brändi, teie konkurentide või mis tahes muu huvipakkuva teema jälgimiseks. Selles artiklis näitame, kuidas luua süsteem, mis kuulab sotsiaalmeediat, nagu Reddit, Hacker News, Linkedin, Twitter jne, ja teostab automaatselt tunnetusanalüüsi sisu kohta tänu genereerivale tehisintellektile.
Sotsiaalse kuulamise kombineerimine tunnetusanalüüsiga brändi tunnete analüüsiks
Sotsiaalne kuulamine on tähelepanu pööramine ja vestluste tõlgendamine mis tahes teemade ümber sotsiaalmeedia platvormidel, ülevaatesaitidel ja muudes veebikanalites.
Sentimentanalüüs on seevastu tekstis väljendatud arvamuste tuvastamine ja liigitamine positiivseks, negatiivseks või neutraalseks. See hõlmab loomuliku keeletöötluse, tekstianalüüsi ja arvutilingvistika kasutamist, et süstemaatiliselt tuvastada, ekstraheerida, kvantifitseerida ja uurida afektiivseid seisundeid ja subjektiivset teavet.
Kui kombineerite sotsiaalse kuulamise ja tunnetusanalüüsi, saate jälgida ja analüüsida oma brändi või konkurentidega seotud vestlustes väljendatud tundeid. Seda tuntakse ka kui "brändi sentimentaalanalüüsi". Brändi sentimentaalanalüüs võimaldab teil automaatselt mõista, kuidas tarbijad teie brändi või konkurentide kohta arvavad, tuvastada parandamist vajavad valdkonnad, hüpata sotsiaalmeedias õigesse vestlusse, et suhelda potentsiaalsete klientidega, ning teha andmepõhiseid otsuseid, et parandada oma brändi mainet ja klientide lojaalsust.
Sotsiaalse kuulamise platvormi loomine
Sotsiaalse kuulamise platvormi loomine eeldab, et ühendate sotsiaalmeedia platvormi ja otsite välja kõik uued postitused ja kommentaarid, mis sisaldavad märksõnu, mida soovite jälgida.
Seda on lihtsam saavutada, kui platvorm, mida kavatsete jälgida, pakub API-d. Näiteks Reddit pakub API-d, mida saate hõlpsasti tarbida. Siin on lihtne cURL päring, mis hangib viimased 100 Redditi postitust:
Ja siin on tüüpiline vastus, mille nende API tagastab:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
Igal sotsiaalmeediaplatvormil on omad nüansid, mida me ei saa kahjuks selles artiklis käsitleda. Selleks, et hõlpsasti jälgida sotsiaalmeediaplatvorme (nagu Reddit, Linkedin, X, Hacker News ja muud), võiksite tellida spetsiaalse sotsiaalse kuulamise platvormi, nagu meie teenus KWatch.io. Proovi KWatch.io tasuta siin.
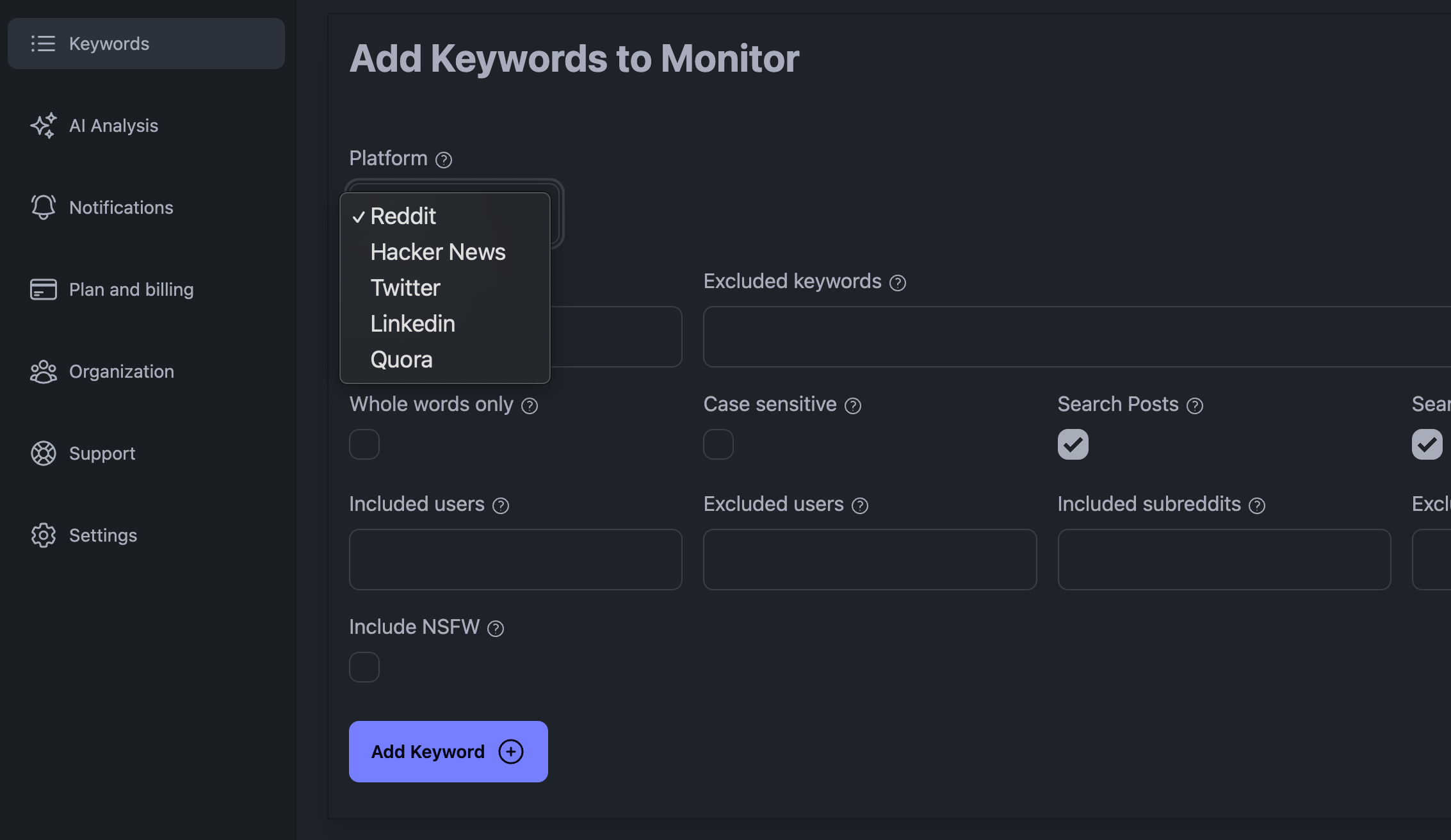
Märksõnade lisamine KWatch.io armatuurlauale
Mõned peamised probleemid sotsiaalmeedia kuulamise puhul on suur andmemaht, mida tuleb käsitleda, asjaolu, et sotsiaalmeedia platvorm võib teid blokeerida, kui teete liiga palju päringuid, ja asjaolu, et peate olema arukas andmete käsitlemisel.
Järgmises jaotises selgitame, kuidas kogutud andmeid oma süsteemi integreerida.
Sotsiaalmeedia andmete integreerimine oma süsteemi
Kui olete sotsiaalmeedia platvormidelt andmed kogunud, peate need salvestama andmebaasi või andmelattu. See võimaldab teil andmeid analüüsida, teostada sentimentaalanalüüsi ja genereerida teadmisi.
Sotsiaalmeedia andmete (mis on põhimõtteliselt puhtalt tekstiandmed) salvestamiseks on mitu võimalust, sõltuvalt teie nõuetest ja andmemahust, millega te tegelete. Mõned levinud võimalused on järgmised:
- Kasutades relatsioonilist andmebaasi nagu MySQL või PostgreSQL
- Kasutades NoSQL-andmebaasi nagu MongoDB või Cassandra
- Andmelao nagu Amazon Redshift või Google BigQuery kasutamine
Kui olete tellinud sotsiaalse kuulamise platvormi, peaksite kontrollima, kas nad pakuvad võimalust andmete ülekandmiseks teie süsteemi.
Veebikonksud, millele sageli viidatakse kui "veebikõnedele" või "HTTP push API-le", on rakenduste jaoks vahendiks, mille abil jagada reaalajas andmeid teiste rakendustega. See saavutatakse HTTP POST-päringute genereerimisega, kui teatavad sündmused toimuvad, edastades seega teavet teistele rakendustele viivitamata.
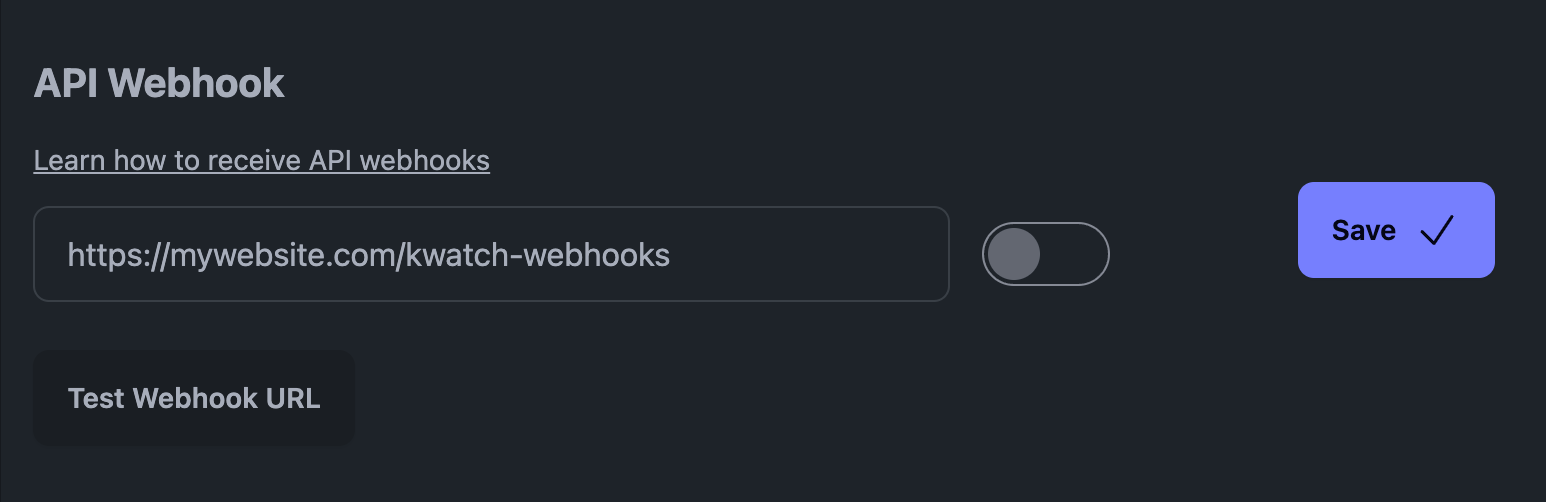
Näiteks meie platvormi KWatch.io puhul peaksite minema jaotisse "teated" ja seadma veebikonksu URL-i, mis viitab teie süsteemile.
API veebikonks KWatch.io's
Siin on näha, milline näeb välja KWatch.io veebikonks (see on JSON-saateleht):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Kui te olete uus, saate neid veebikonksusid Pythonis hõlpsasti vastu võtta, kasutades FastAPI-d.
Paigaldage FastAPI koos Uvicorn serveriga:
pip install fastapi uvicorn
Nüüd looge uus Python-fail ja kleebige järgmine kood (võib-olla peate seda skripti kohandama):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Salvestage fail ja käivitage server järgmise käsuga:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
Teie server töötab nüüd ja on valmis võtma vastu veebikonksu KWatch.io'lt.
Sentimentanalüüsi teostamine andmetel koos generatiivsete tehisintellekti mudelitega nagu GPT-4 või LLaMA 3
Kui olete sotsiaalmeedia andmed kogunud ja salvestanud, saate neid analüüsida.
Tänapäeval on kõige täpsem viis konkreetse märksõna kohta käiva teksti analüüsimiseks kasutada genereerivaid tehisintellekti mudeleid, nagu GPT-4, LLaMA 3, ChatDolphin jne. Need LL-mudelid ei ole tingimata kiired ja võivad olla mastaabis kulukad, kuid nad tagavad tipptasemel tulemused. Kui teil on vaja analüüsida väga suurt hulka märksõnu, võite vähendada kulusid, kasutades väiksemaid mudeleid, või häälestada omaenda mudelit.
Sa võid kasutada oma tehisintellekti mudelit või ühendada AI API-d, nagu OpenAI või NLP Cloud. Selles artiklis kasutame NLP Cloud AI API-d.
Teie taotlus ei pea olema liiga keeruline. Näiteks siin on kommentaar Redditil OpenAI kohta:
Kommentaar Redditi kohta OpenAI kohta
Kasutame NLP Cloudi mudelit ChatDolphin, et analüüsida selles Redditi kommentaaris OpenAI kohta käivaid meeleolusid. Kõigepealt installime NLP Cloudi Pythoni kliendi:
pip install nlpcloud
Nüüd saate analüüsida Redditi kommentaari sentimenti järgmise Python-koodiga:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
Vastus on järgmine:
Negative
Nüüd lõpetame ja kirjutame lõpliku koodi, mis kuulab API veebikonksu ja teostab andmetel sentimentaalanalüüsi:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Kokkuvõte
Nagu näete, on võimalik automatiseerida sotsiaalmeedia andmete sentimentaalanalüüsi kaasaegsete genereerivate tehisintellekti mudelite ja tõhusate sotsiaalse kuulamise tööriistade abil. Seda lähenemisviisi saab rakendada erinevates sotsiaalmeedia jälgimise stsenaariumides. Siin on mõned ideed:
- Oma kaubamärgi maine jälgimine
- Konkurendi maine jälgimine
- Aktsiaoptsiooni ümbritsevatel meeleoludel silma peal hoidmine
- Konkreetse tehnoloogilise suundumusega, näiteks tehisintellekti või krüpto, seotud meeleolu jälgimine.
- ...
Sellise programmi tootmine võib siiski olla keeruline. Esiteks seetõttu, et sotsiaalmeediat ei ole nii lihtne jälgida, aga ka seetõttu, et genereerivate tehisintellekti mudelite kasutamine suurte andmemahtude puhul võib olla kulukas.
Kui te ei soovi sellist süsteemi ise luua ja hooldada, soovitame selle asemel kasutada meie platvormi KWatch.io, kuna me jälgime automaatselt sotsiaalmeediat ja teostame tuvastatud postituste ja kommentaaride kohta sentimentaalanalüüsi: registreeru KWatch.io's siin.
 KWatch.io
KWatch.io