Så här bygger du en pipeline för sentimentanalys av sociala medier
Sentimentanalys på sociala medier kan vara mycket användbart för att övervaka ditt varumärke, dina konkurrenter eller något annat ämne av intresse. I den här artikeln visar vi hur du bygger ett system som lyssnar på sociala medier som Reddit, Hacker News, Linkedin, Twitter etc. och automatiskt utför sentimentanalys på innehållet tack vare generativ AI.
Kombinera social lyssning med sentimentsanalys för sentimentsanalys av varumärken
Social listening innebär att man uppmärksammar och tolkar konversationer om olika ämnen på sociala medier, recensionssajter och andra onlinekanaler.
Sentimentanalys, å andra sidan, är en process där man identifierar och kategoriserar åsikter som uttrycks i en text som positiva, negativa eller neutrala. Det handlar om att använda naturlig språkbehandling, textanalys och datorlingvistik för att systematiskt identifiera, extrahera, kvantifiera och studera affektiva tillstånd och subjektiv information.
När du kombinerar social listening och sentimentanalys kan du spåra och analysera den känsla som uttrycks i konversationer relaterade till ditt varumärke eller dina konkurrenter. Detta kallas också för "varumärkessentimentanalys". Med hjälp av sentimentanalys av varumärken kan du automatiskt förstå vad konsumenterna tycker om ditt varumärke eller dina konkurrenter, identifiera förbättringsområden, hoppa in i rätt konversation på sociala medier för att engagera dig med potentiella kunder och fatta datadrivna beslut för att förbättra ditt varumärkes rykte och kundlojalitet.
Bygga en plattform för social lyssning
För att skapa en plattform för social listening krävs att du ansluter dig till en plattform för sociala medier och hämtar alla nya inlägg och kommentarer som innehåller de nyckelord du vill övervaka.
Detta är lättare att uppnå om den plattform du planerar att övervaka exponerar ett API. Till exempel exponerar Reddit ett API som du enkelt kan konsumera. Här är en enkel cURL-begäran som hämtar de senaste 100 Reddit-inläggen:
Och här är ett typiskt svar som returneras av deras API:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
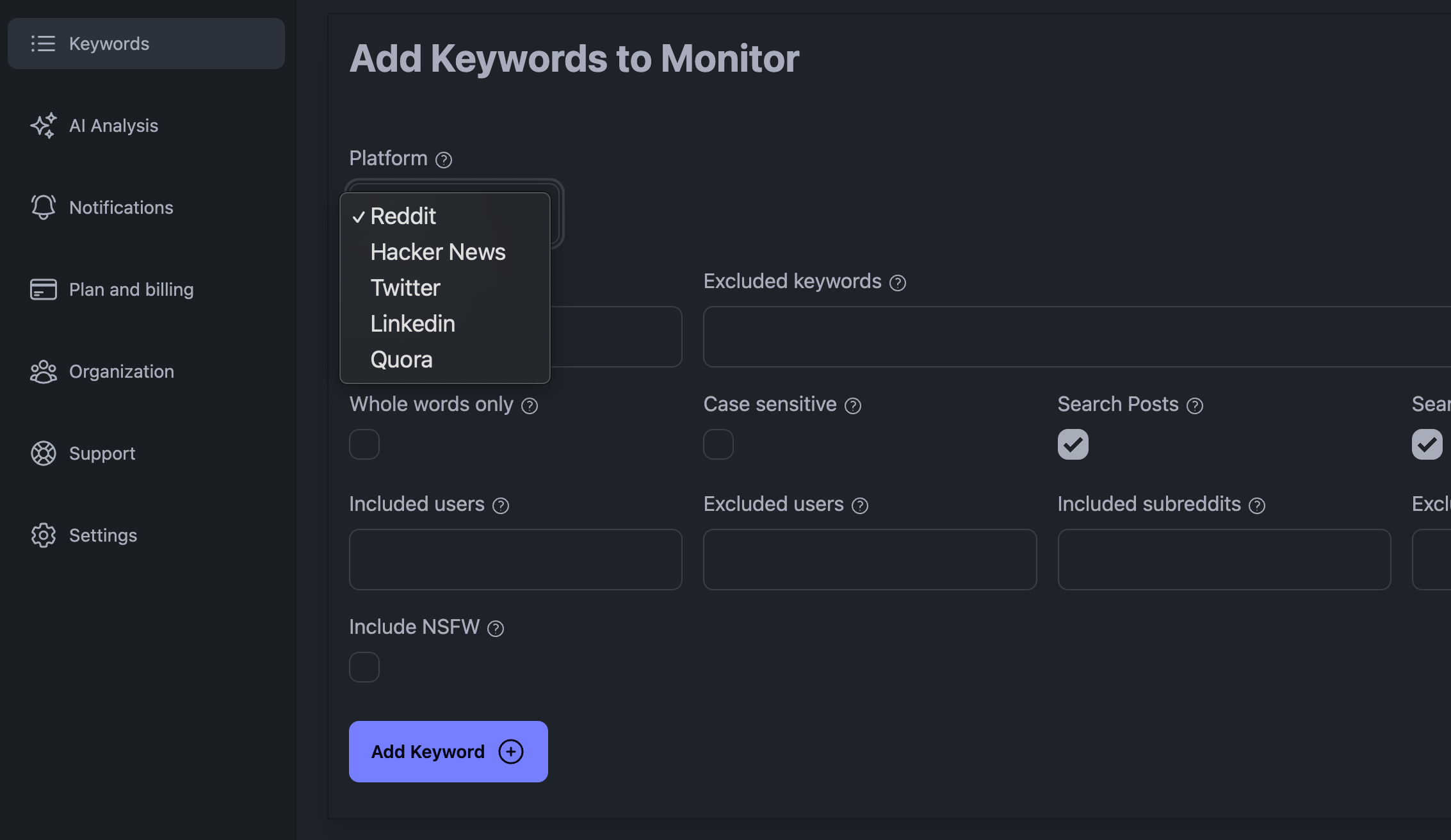
Varje social medieplattform har sina egna finesser som vi tyvärr inte kan täcka i den här artikeln. För att enkelt kunna övervaka sociala medieplattformar (som Reddit, Linkedin, X, Hacker News, med flera), kanske du vill prenumerera på en dedikerad social lyssningsplattform som vår KWatch.io-tjänst. Prova KWatch.io gratis här.
Lägg till nyckelord i din KWatch.io-kontrollpanel
Några av de största utmaningarna med att lyssna på sociala medier är den stora mängd data som du måste hantera, det faktum att du kan bli blockerad av den sociala medieplattformen om du gör för många förfrågningar och det faktum att du måste vara smart när du hanterar data.
I nästa avsnitt förklarar vi hur du integrerar de insamlade uppgifterna i ditt system.
Integrera data från sociala medier i ditt system
När du har samlat in data från sociala medieplattformar måste du lagra dem i en databas eller ett datalager. Detta gör att du kan analysera data, utföra sentimentanalys och generera insikter.
Det finns flera sätt att lagra data från sociala medier (som i princip är ren textdata), beroende på dina krav och den datamängd du hanterar. Några vanliga alternativ inkluderar:
- Använda en relationsdatabas som MySQL eller PostgreSQL
- Använda en NoSQL-databas som MongoDB eller Cassandra
- Använda ett datalager som Amazon Redshift eller Google BigQuery
Om du har prenumererat på en social listening-plattform bör du kontrollera om de erbjuder ett sätt att överföra data till ditt system.
Webhooks, som ofta kallas "web callbacks" eller "HTTP push API", är ett sätt för applikationer att dela realtidsdata med andra applikationer. Detta uppnås genom att generera HTTP POST-förfrågningar när specifika händelser inträffar och därmed leverera information till andra applikationer omedelbart.
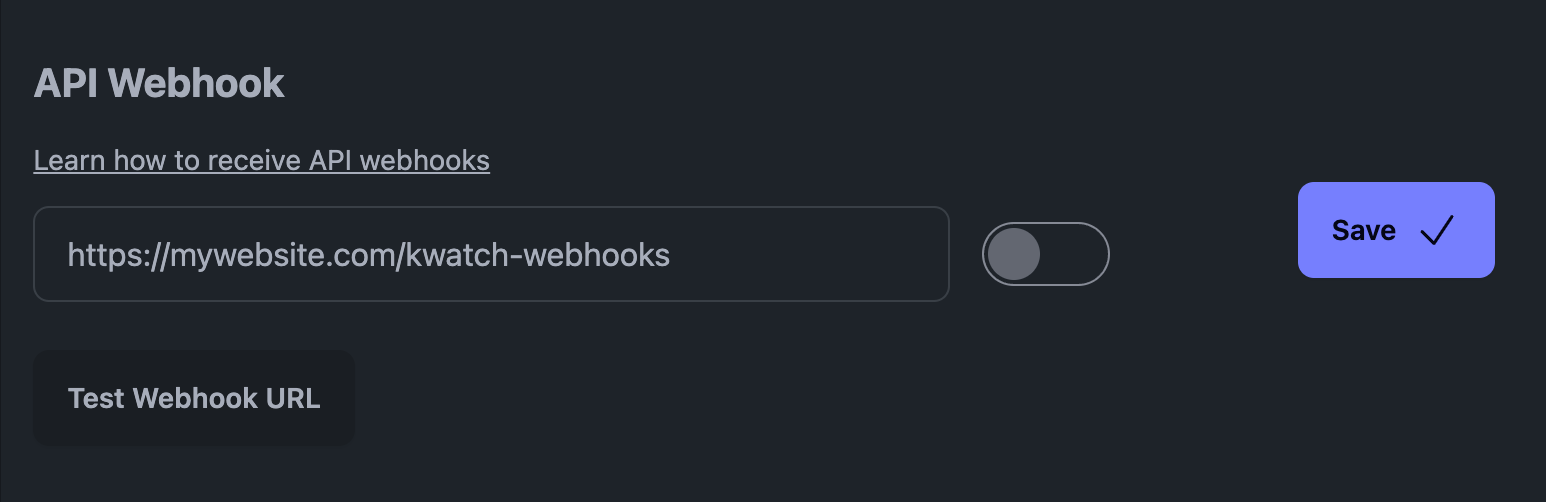
Till exempel på vår plattform, KWatch.io, bör du gå till avsnittet "meddelanden" och ställa in en webhook URL som pekar på ditt system.
API-webbhook på KWatch.io
Så här ser KWatch.io webhook ut (det är en JSON-nyttolast):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Om du är ny på det här kan du enkelt ta emot dessa webhooks i Python med hjälp av FastAPI.
Installera FastAPI med Uvicorn-servern:
pip install fastapi uvicorn
Skapa nu en ny Python-fil och klistra in följande kod (du kan behöva anpassa detta skript):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Spara filen och kör servern med följande kommando:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
Din server är nu igång och redo att ta emot webhooks från KWatch.io.
Sentimentanalys av data med generativa AI-modeller som GPT-4 eller LLaMA 3
När du har samlat in och lagrat data från sociala medier kan du göra en sentimentanalys av dem.
Idag är det mest exakta sättet att utföra sentimentanalys på ett stycke text om ett specifikt nyckelord genom att använda generativa AI-modeller som GPT-4, LLaMA 3, ChatDolphin etc. Dessa LLM:er är inte nödvändigtvis snabba och kan vara kostsamma i stor skala, men de garanterar toppmoderna resultat. Om du behöver analysera mycket stora volymer av sökord kanske du vill sänka kostnaderna genom att använda mindre modeller eller finjustera din egen modell.
Du kan distribuera din egen AI-modell eller ansluta till ett AI API som OpenAI eller NLP Cloud. I den här artikeln kommer vi att ansluta till NLP Cloud AI API.
Din begäran behöver inte vara alltför komplicerad. Här är till exempel en kommentar på Reddit om OpenAI:
En kommentar på Reddit om OpenAI
Låt oss använda ChatDolphin-modellen på NLP Cloud för att analysera känslan om OpenAI i denna Reddit-kommentar. Först installerar du NLP Cloud Python-klienten:
pip install nlpcloud
Nu kan du analysera känslan av Reddit-kommentaren med följande Python-kod:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
Svaret kommer att bli:
Negative
Nu avslutar vi och skriver den slutliga koden som lyssnar på API-webhooken och utför sentimentanalys på data:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Slutsats
Som du kan se är det möjligt att automatisera sentimentanalys av data från sociala medier med hjälp av moderna generativa AI-modeller och effektiva verktyg för social lyssning. Detta tillvägagångssätt kan tillämpas i olika scenarier för övervakning av sociala medier. Här är några idéer:
- Spårning av ditt varumärkes anseende
- Spårning av en konkurrents rykte
- Hålla ett öga på sentimentet kring en aktieoption
- Övervakning av sentimentet kring en specifik teknisk trend, t.ex. AI eller krypto
- ...
Att producera ett sådant program kan dock vara en utmaning. För det första eftersom sociala medier inte är så lätta att övervaka, men också eftersom generativa AI-modeller kan vara kostsamma att använda på stora datamängder.
Om du inte vill bygga upp och underhålla ett sådant system själv rekommenderar vi att du istället använder vår plattform KWatch.io, eftersom vi automatiskt övervakar sociala medier och utför sentimentanalys på de inlägg och kommentarer som upptäcks: registrera dig på KWatch.io här.
 KWatch.io
KWatch.io