Sådan opbygger du en pipeline til sentimentsanalyse af sociale medier
Sentimentanalyse på sociale medier kan være meget nyttig til at overvåge dit brand, dine konkurrenter eller ethvert andet emne af interesse. I denne artikel viser vi dig, hvordan du bygger et system, der lytter til sociale medier som Reddit, Hacker News, Linkedin, Twitter osv. og automatisk udfører sentimentanalyse på indholdet takket være generativ AI.
Kombination af social lytning og sentimentanalyse til analyse af brand-sentimenter
Social lytning er at være opmærksom på og fortolke samtaler om et hvilket som helst emne på sociale medieplatforme, anmeldelsessider og andre onlinekanaler.
Sentimentanalyse er på den anden side processen med at identificere og kategorisere meninger, der udtrykkes i et stykke tekst, som positive, negative eller neutrale. Det indebærer brug af naturlig sprogbehandling, tekstanalyse og computerlingvistik til systematisk at identificere, udtrække, kvantificere og studere affektive tilstande og subjektiv information.
Når du kombinerer social lytning og sentimentanalyse, kan du spore og analysere den stemning, der kommer til udtryk i samtaler om dit brand eller dine konkurrenter. Dette er også kendt som "brand sentiment analysis". Brand sentiment analysis giver dig mulighed for automatisk at forstå, hvad forbrugerne mener om dit brand eller dine konkurrenter, identificere områder, der kan forbedres, hoppe ind i den rigtige samtale på sociale medier for at komme i kontakt med potentielle kunder og træffe datadrevne beslutninger for at forbedre dit brands omdømme og kundeloyalitet.
Opbygning af en social lytteplatform
At skabe en social lytteplatform kræver, at du kobler dig på en social medieplatform og henter alle nye indlæg og kommentarer, der indeholder de nøgleord, du vil overvåge.
Det er lettere at opnå, hvis den platform, du planlægger at overvåge, har en API. Reddit har f.eks. en API, som du nemt kan bruge. Her er en simpel cURL-anmodning, der henter de sidste 100 Reddit-indlæg:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
Hver social medieplatform har sine egne finesser, som vi desværre ikke kan dække i denne artikel. For nemt at kunne overvåge sociale medieplatforme (som Reddit, Linkedin, X, Hacker News m.fl.) kan det være en god idé at abonnere på en dedikeret social lytteplatform som vores KWatch.io-tjeneste. Prøv KWatch.io gratis her.
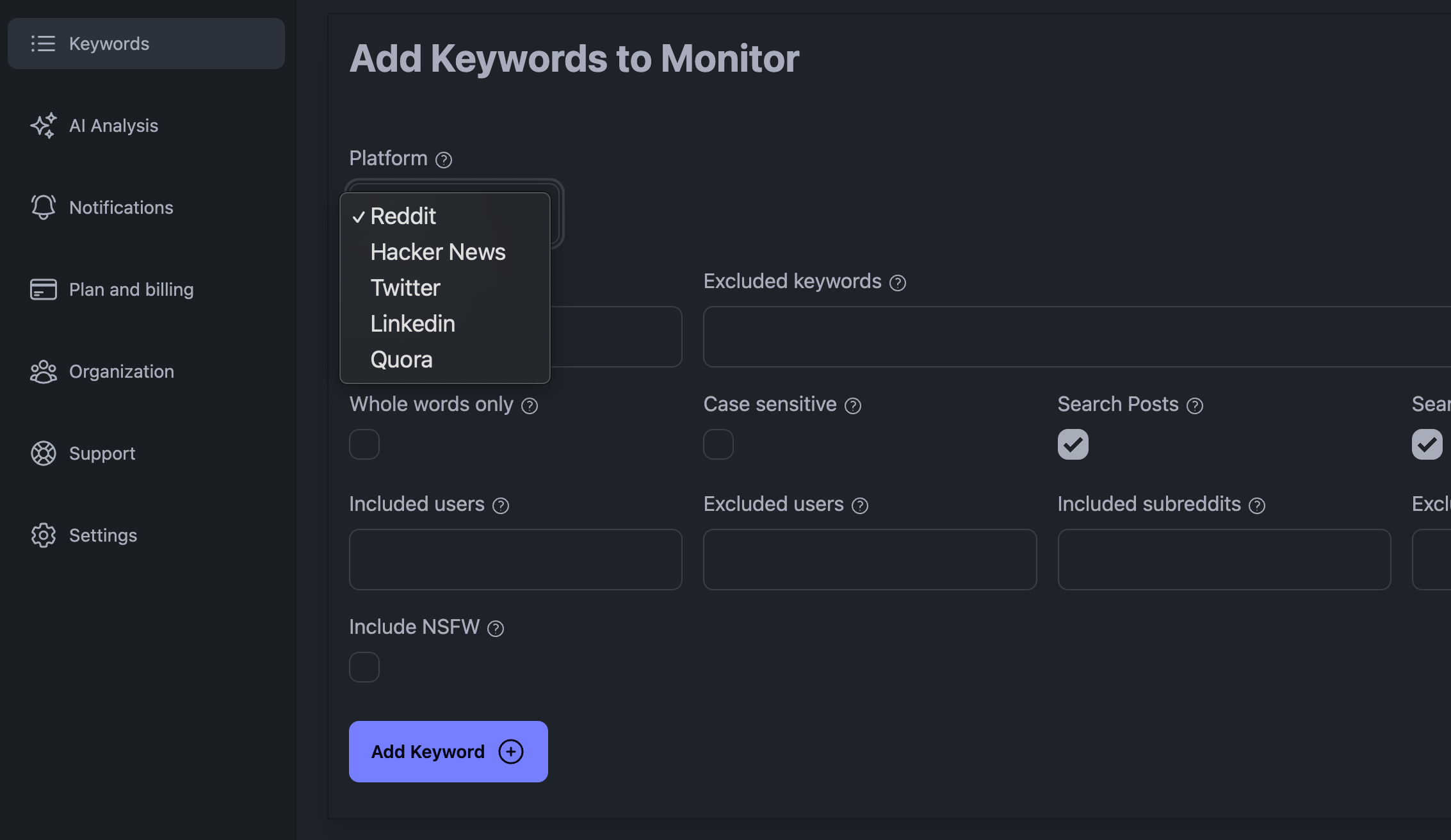
Tilføj nøgleord i dit KWatch.io-dashboard
Nogle af de største udfordringer, når man lytter til sociale medier, er den store mængde data, man skal håndtere, det faktum, at man kan blive blokeret af den sociale medieplatform, hvis man kommer med for mange anmodninger, og det faktum, at man skal være smart med hensyn til den måde, man håndterer dataene på.
I næste afsnit forklarer vi, hvordan du integrerer de indsamlede data i dit system.
Integrering af data fra sociale medier i dit system
Når du har indsamlet data fra sociale medieplatforme, skal du gemme dem i en database eller et datalager. Det giver dig mulighed for at analysere dataene, udføre sentimentanalyse og generere indsigt.
Der er flere måder at gemme data fra sociale medier (som dybest set er rene tekstdata) på, afhængigt af dine krav og den mængde data, du har med at gøre. Nogle almindelige muligheder omfatter:
- Brug af en relationsdatabase som MySQL eller PostgreSQL
- Brug af en NoSQL-database som MongoDB eller Cassandra
- Brug af et datalager som Amazon Redshift eller Google BigQuery
Hvis du abonnerer på en social lytteplatform, bør du tjekke, om de tilbyder en måde at overføre data til dit system på.
Webhooks, ofte kaldet "web callbacks" eller "HTTP push API", fungerer som et middel for applikationer til at dele realtidsdata med andre applikationer. Dette opnås ved at generere HTTP POST-anmodninger, når specifikke begivenheder finder sted, og dermed levere oplysninger til andre applikationer med det samme.
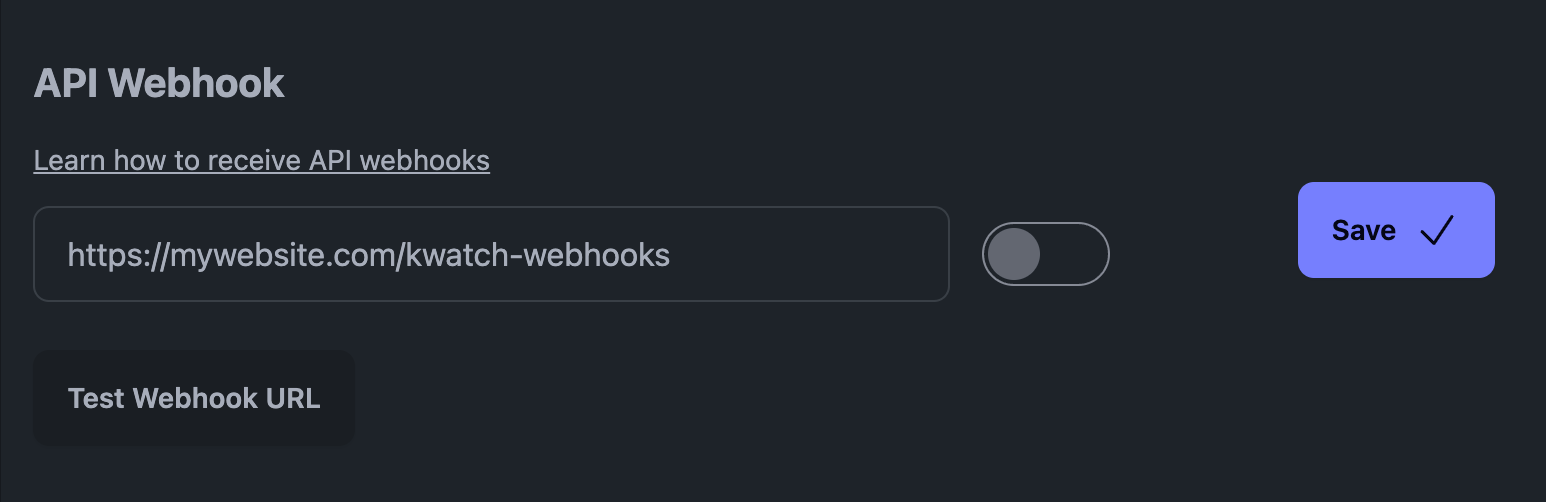
På vores platform, KWatch.io, skal du f.eks. gå til afsnittet "notifikationer" og indstille en webhook-URL, der peger på dit system.
API-webhook på KWatch.io
Sådan ser KWatch.io webhook ud (det er en JSON-nyttelast):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Hvis det er nyt for dig, kan du nemt modtage disse webhooks i Python ved hjælp af FastAPI.
Installer FastAPI med Uvicorn-serveren:
pip install fastapi uvicorn
Opret nu en ny Python-fil, og indsæt følgende kode (det kan være nødvendigt at tilpasse dette script):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Gem filen, og kør serveren med følgende kommando:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
Din server kører nu og er klar til at modtage webhooks fra KWatch.io.
Udførelse af sentimentanalyse på data med generative AI-modeller som GPT-4 eller LLaMA 3
Når du har indsamlet og gemt data fra de sociale medier, kan du udføre sentimentanalyse på dem.
I dag er den mest præcise måde at udføre sentimentanalyse på et stykke tekst om et specifikt nøgleord ved at bruge generative AI-modeller som GPT-4, LLaMA 3, ChatDolphin osv. Disse LLM'er er ikke nødvendigvis hurtige og kan være dyre i stor skala, men de garanterer topmoderne resultater. Hvis du har brug for at analysere meget store mængder søgeord, kan du måske sænke omkostningerne ved at bruge mindre modeller eller finjustere din egen model.
Du kan implementere din egen AI-model eller tilslutte dig en AI-API som OpenAI eller NLP Cloud. I denne artikel vil vi tilslutte os NLP Cloud AI API.
Din anmodning behøver ikke at være alt for kompleks. Her er for eksempel en kommentar på Reddit om OpenAI:
En kommentar på Reddit om OpenAI
Lad os bruge ChatDolphin-modellen på NLP Cloud til at analysere stemningen omkring OpenAI i denne Reddit-kommentar. Først skal du installere NLP Cloud Python-klienten:
pip install nlpcloud
Nu kan du analysere stemningen i Reddit-kommentaren med følgende Python-kode:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
Svaret vil være:
Negative
Lad os nu afslutte og skrive den endelige kode, der lytter til API-webhook'et og udfører sentimentanalyse på dataene:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Konklusion
Som du kan se, er det muligt at automatisere sentimentanalyse på sociale mediedata ved hjælp af moderne generative AI-modeller og effektive sociale lytteværktøjer. Denne tilgang kan anvendes i forskellige scenarier for overvågning af sociale medier. Her er nogle ideer:
- Sporing af dit brands omdømme
- Sporing af en konkurrents omdømme
- Hold øje med stemningen omkring en aktieoption
- Overvågning af stemningen i forbindelse med en specifik teknologisk tendens, f.eks. kunstig intelligens eller krypto
- ...
Det kan dog være en udfordring at producere sådan et program. For det første fordi sociale medier ikke er så lette at overvåge, men også fordi generative AI-modeller kan være dyre at bruge på store datamængder.
Hvis du ikke selv ønsker at opbygge og vedligeholde et sådant system, anbefaler vi, at du i stedet bruger vores KWatch.io-platform, da vi automatisk overvåger sociale medier og udfører sentimentanalyse på de fundne indlæg og kommentarer: registrer dig på KWatch.io her.
 KWatch.io
KWatch.io