Hogyan építsünk egy közösségi média hangulatelemző csővezetéket?
A közösségi média hangulatelemzése nagyon hasznos lehet a márka, a versenytársak vagy bármely más érdekes téma nyomon követéséhez. Ebben a cikkben megmutatjuk, hogyan építhetünk egy olyan rendszert, amely a közösségi médiát, például a Redditet, a Hacker News-t, a Linkedint, a Twittert stb. hallgatja, és a generatív mesterséges intelligenciának köszönhetően automatikusan elvégzi a tartalom hangulatelemzését.
A közösségi figyelés és a hangulatelemzés kombinálása a márkahangulat elemzéséhez
A közösségi figyelés a közösségi média platformokon, értékelő oldalakon és más online csatornákon bármilyen témával kapcsolatos beszélgetésekre való odafigyelés és azok értelmezése.
Az érzelemelemzés másrészt a szövegben kifejezett vélemények azonosításának és pozitív, negatív vagy semleges kategóriákba sorolásának folyamata. A természetes nyelvi feldolgozás, a szövegelemzés és a számítógépes nyelvészet felhasználásával szisztematikusan azonosítja, kivonja, számszerűsíti és tanulmányozza az érzelmi állapotokat és a szubjektív információkat.
A közösségi figyelés és a hangulatelemzés kombinálásával nyomon követheti és elemezheti a márkájával vagy versenytársaival kapcsolatos beszélgetésekben kifejezett hangulatot. Ezt "márkaérzelemzésnek" is nevezik. A márkaérzelem-elemzés lehetővé teszi, hogy automatikusan megértse, hogyan vélekednek a fogyasztók az Ön márkájáról vagy versenytársairól, azonosítsa a fejlesztendő területeket, a megfelelő beszélgetésbe ugorjon bele a közösségi médiában a potenciális ügyfelekkel való kapcsolattartás érdekében, és adatvezérelt döntéseket hozzon a márka hírnevének és ügyfélhűségének javítása érdekében.
Közösségi figyelő platform építése
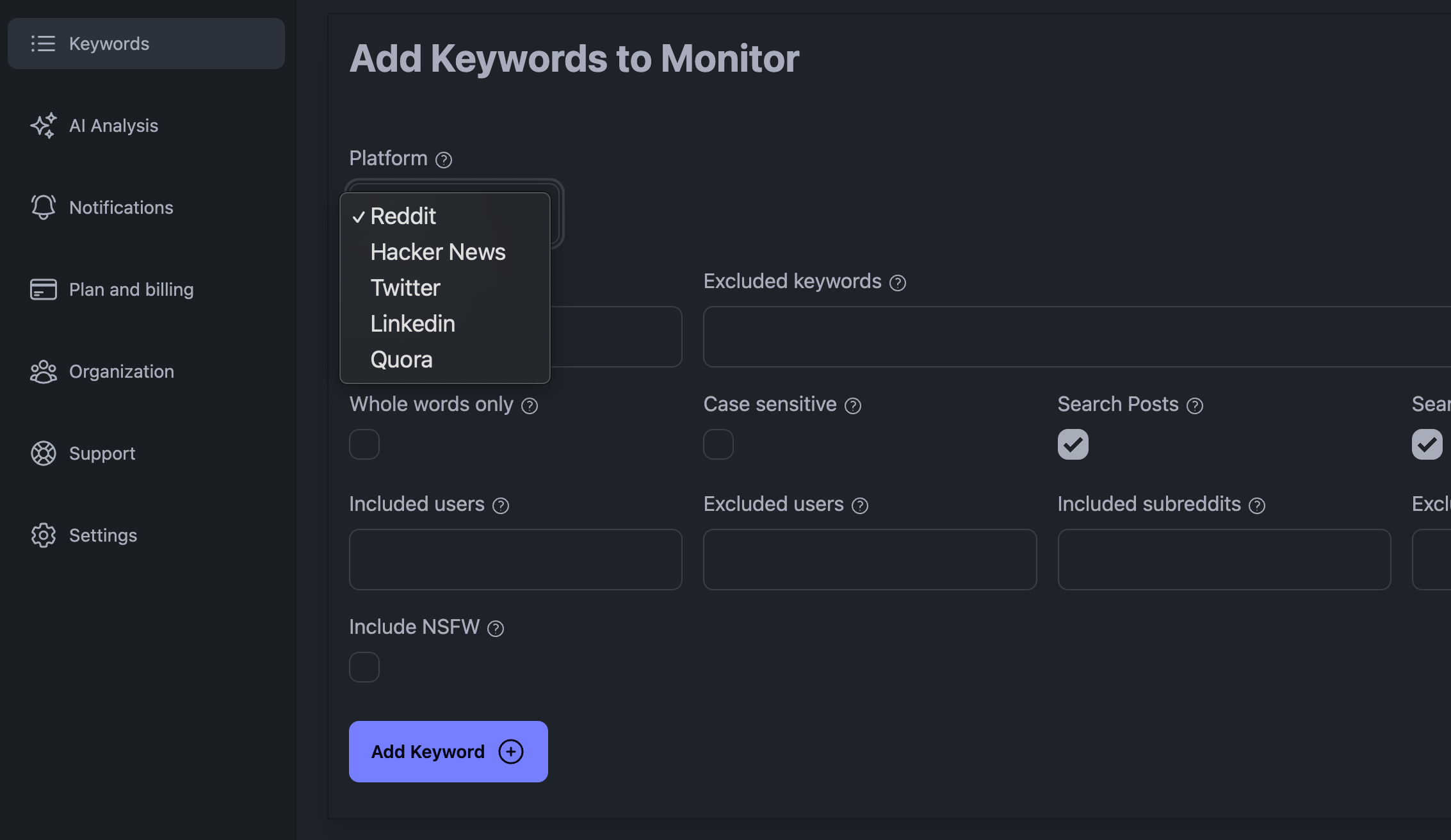
A közösségi figyelőplatform létrehozásához be kell csatlakoznia egy közösségi médiaplatformba, és le kell kérnie minden olyan új bejegyzést és hozzászólást, amely tartalmazza a nyomon követni kívánt kulcsszavakat.
Ez könnyebben megvalósítható, ha a megfigyelni kívánt platform API-t bocsát ki. A Reddit például egy olyan API-t tesz közzé, amelyet könnyen felhasználhat. Íme egy egyszerű cURL-kérés, amely lekérdezi az utolsó 100 Reddit-bejegyzést:
Itt pedig egy tipikus válasz, amelyet az API-juk küld vissza:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
Minden egyes közösségi médiaplatformnak megvannak a maga finomságai, amelyekkel ebben a cikkben sajnos nem tudunk foglalkozni. A közösségi médiaplatformok (például a Reddit, a Linkedin, az X, a Hacker News és mások) egyszerű nyomon követése érdekében érdemes feliratkoznia egy dedikált közösségi figyelő platformra, például a KWatch.io szolgáltatásunkra. Próbálja ki a KWatch.io-t ingyenesen itt.
Kulcsszavak hozzáadása a KWatch.io műszerfalon
A közösségi médiameghallgatás során a fő kihívások közé tartozik a nagy mennyiségű adat, amelyet kezelni kell, az a tény, hogy a közösségi médiaplatform blokkolhatja Önt, ha túl sok kérést tesz, és az a tény, hogy okosan kell kezelnie az adatokat.
A következő szakaszban elmagyarázzuk, hogyan lehet az összegyűjtött adatokat integrálni a rendszerbe.
A közösségi médiaadatok integrálása a rendszerbe
Miután összegyűjtötte az adatokat a közösségi médiaplatformokról, azokat egy adatbázisban vagy adattárházban kell tárolnia. Ez lehetővé teszi az adatok elemzését, az érzelemelemelemzés elvégzését és a meglátások generálását.
A közösségi médiaadatok (amelyek alapvetően tiszta szöveges adatok) tárolásának több módja is létezik, az Ön igényeitől és a kezelt adatmennyiségtől függően. Néhány gyakori lehetőség a következő:
- Relációs adatbázis, mint például a MySQL vagy a PostgreSQL használata
- NoSQL adatbázis használata, mint a MongoDB vagy a Cassandra
- Adattárház használata, mint például az Amazon Redshift vagy a Google BigQuery
Ha feliratkozott egy közösségi figyelő platformra, ellenőrizze, hogy kínálnak-e módot az adatok átvitelére az Ön rendszerébe.
A webhookok, amelyeket gyakran "webes visszahívásoknak" vagy "HTTP push API"-nak is neveznek, az alkalmazások számára a valós idejű adatok más alkalmazásokkal való megosztását szolgálják. Ezt úgy érik el, hogy bizonyos események bekövetkezésekor HTTP POST-kéréseket generálnak, és így az információkat azonnal eljuttatják más alkalmazásokhoz.
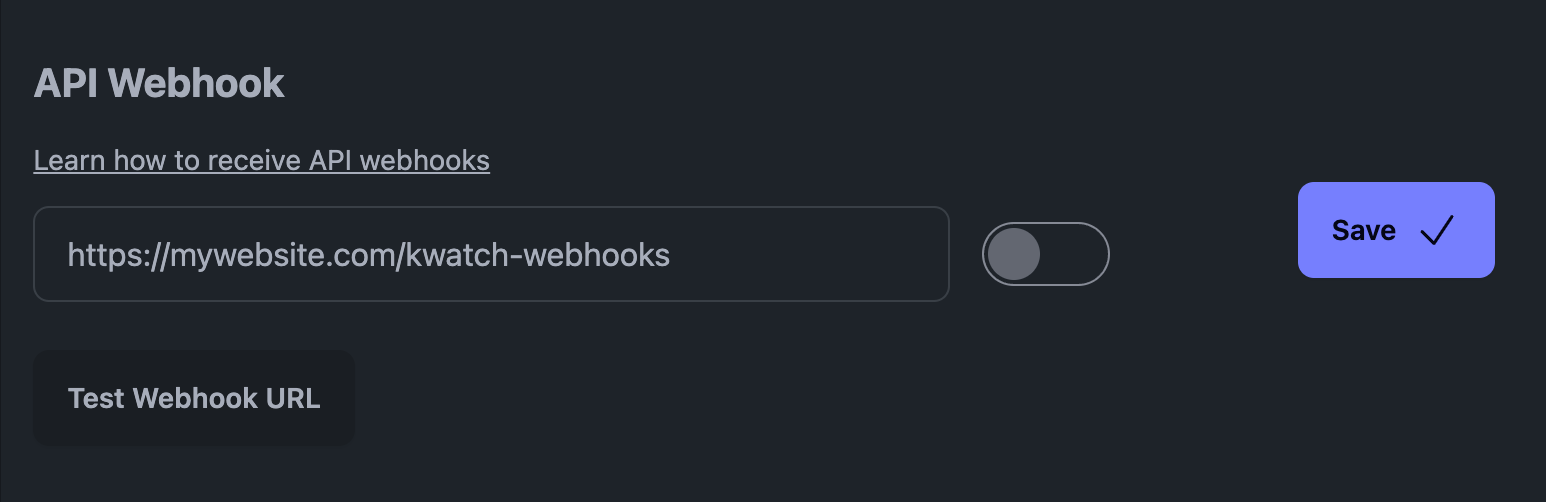
Például a mi platformunkon, a KWatch.io-n, az "értesítések" szakaszba kell lépnie, és be kell állítania egy webhook URL-t, amely a rendszerére mutat.
API Webhook a KWatch.io-n
Így néz ki a KWatch.io webhook (ez egy JSON payload):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Ha új vagy ebben a témában, a FastAPI segítségével könnyedén fogadhatod ezeket a webhookokat Pythonban.
Telepítse a FastAPI-t az Uvicorn szerverrel:
pip install fastapi uvicorn
Most hozzon létre egy új Python fájlt, és illessze be a következő kódot (lehet, hogy át kell alakítania ezt a szkriptet):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Mentse a fájlt, és futtassa a kiszolgálót a következő paranccsal:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
A kiszolgálója most már fut, és készen áll a KWatch.io webhooks fogadására.
Érzelemelemzés elvégzése az adatokon olyan generatív AI modellekkel, mint a GPT-4 vagy a LLaMA 3
Miután összegyűjtötte és tárolta a közösségi médiaadatokat, elvégezheti rajtuk a hangulatelemzést.
Ma a legpontosabb módja annak, hogy egy adott kulcsszóval kapcsolatos szöveges elemzést végezzünk egy adott szövegdarabon, az olyan generatív AI modellek használata, mint a GPT-4, LLaMA 3, ChatDolphin stb. Ezek az LLM-ek nem feltétlenül gyorsak és méretarányosan költségesek lehetnek, de garantálják a legkorszerűbb eredményeket. Ha nagyon nagy mennyiségű kulcsszót kell elemeznie, érdemes kisebb modellek használatával csökkenteni a költségeket, vagy finomhangolni a saját modelljét.
Telepítheti saját AI-modelljét, vagy csatlakozhat egy AI API-hoz, például az OpenAI-hoz vagy az NLP Cloudhoz. Ebben a cikkben az NLP Cloud AI API-hoz csatlakozunk.
A kérésnek nem kell túl bonyolultnak lennie. Itt van például egy hozzászólás a Redditen, az OpenAI-ról:
Egy megjegyzés a Redditen az OpenAI-ról
Használjuk a ChatDolphin modellt az NLP Cloudon, hogy elemezzük az OpenAI-ról alkotott véleményt ebben a Reddit-kommentben. Először is telepítsük az NLP Cloud Python kliensét:
pip install nlpcloud
Most már elemezheti a Reddit-kommentár hangulatát a következő Python-kóddal:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
A válasz a következő lesz:
Negative
Most csomagoljuk be és írjuk meg a végső kódot, amely az API webhookot hallgatja, és az adatokon érzelemelemelemzést végez:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Következtetés
Mint látható, a közösségi médiaadatokon végzett hangulatelemzés automatizálható a modern generatív AI modellek és a hatékony közösségi figyelőeszközök segítségével. Ez a megközelítés különböző közösségi médiafigyelési forgatókönyvekben alkalmazható. Íme néhány ötlet:
- Márkája hírnevének nyomon követése
- A versenytársak hírnevének nyomon követése
- A részvényopciót övező érzelmek figyelemmel kísérése
- Egy adott technológiai trendhez, például a mesterséges intelligenciához vagy a kriptográfiához kapcsolódó érzelmek nyomon követése.
- ...
Egy ilyen program előállítása azonban kihívást jelenthet. Egyrészt azért, mert a közösségi médiát nem olyan könnyű nyomon követni, másrészt pedig azért, mert a generatív AI-modellek nagy mennyiségű adatra való alkalmazása költséges lehet.
Ha nem szeretne saját maga kiépíteni és fenntartani egy ilyen rendszert, javasoljuk, hogy használja helyette a KWatch.io platformunkat, mivel mi automatikusan figyeljük a közösségi médiát, és érzelemelemelemzést végzünk az észlelt posztokon és kommenteken: regisztráljon a KWatch.io-n itt.
 KWatch.io
KWatch.io