Miten rakentaa sosiaalisen median tunteiden analyysiputki
Sosiaalisen median tunneanalyysi voi olla erittäin hyödyllinen seurattaessa brändiäsi, kilpailijoitasi tai mitä tahansa muuta kiinnostavaa aihetta. Tässä artikkelissa näytämme, miten rakennetaan järjestelmä, joka kuuntelee sosiaalista mediaa, kuten Redditiä, Hacker Newsia, Linkediniä, Twitteriä jne., ja suorittaa sisällöstä automaattisesti sentimenttianalyysin generatiivisen tekoälyn ansiosta.
Sosiaalisen kuuntelun ja tunneanalyysin yhdistäminen brändin tunneanalyysia varten
Sosiaalinen kuuntelu on sosiaalisen median alustoilla, arvostelusivustoilla ja muissa verkkokanavissa käytävien keskustelujen seuraamista ja tulkitsemista.
Tunneanalyysi puolestaan on prosessi, jossa tunnistetaan ja luokitellaan tekstissä ilmaistut mielipiteet positiivisiksi, negatiivisiksi tai neutraaleiksi. Siinä käytetään luonnollisen kielen käsittelyä, tekstianalyysiä ja laskennallista kielitiedettä systemaattisesti tunnistaakseen, poimiakseen, kvantifioidakseen ja tutkiakseen affektiivisia tiloja ja subjektiivista tietoa.
Kun yhdistät sosiaalisen kuuntelun ja tunneanalyysin, voit seurata ja analysoida brändiisi tai kilpailijoihisi liittyvissä keskusteluissa ilmaistuja tunteita. Tämä tunnetaan myös nimellä "brändin sentimenttianalyysi". Brändin sentimenttianalyysin avulla voit automaattisesti ymmärtää, mitä mieltä kuluttajat ovat brändistäsi tai kilpailijoistasi, tunnistaa parannusalueita, hypätä oikeaan keskusteluun sosiaalisessa mediassa saadaksesi yhteyden potentiaalisiin asiakkaisiin ja tehdä tietoon perustuvia päätöksiä, joilla parannat brändisi mainetta ja asiakasuskollisuutta.
Sosiaalisen kuuntelualustan rakentaminen
Sosiaalisen kuuntelualustan luominen edellyttää, että liityt sosiaalisen median alustaan ja haet kaikki uudet viestit ja kommentit, jotka sisältävät avainsanoja, joita haluat seurata.
Tämä onnistuu helpommin, jos alusta, jota aiot valvoa, tarjoaa API:n. Esimerkiksi Reddit tarjoaa API:n, jota voit helposti käyttää. Tässä on yksinkertainen cURL-pyyntö, joka hakee 100 viimeisintä Reddit-postausta:
Ja tässä on tyypillinen vastaus, jonka heidän API:nsa palauttaa:
{
"kind": "Listing",
"data": {
"after": "t3_1asad4n",
"dist": 100,
"modhash": "ne8fi0fr55b56b8a75f8075df95fa2f03951cb5812b0f9660d",
"geo_filter": "",
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "GunAccessoriesForSale",
"selftext": "Morning gents. I\u2019m looking to snag up your forgotten factory yellow spring for the 509T. I need to source one for a buddy who lost his and I cannot find any available anywhere! \n\nIf one of you have the yellow spring laying around, looking to pay $50 shipped\u2026 \n\nTo my 509t owners, it\u2019s the \u201clight\u201d spring that comes in a plastic bag in the carrying case. \n\nThanks in advance ",
"author_fullname": "t2_2ezh71n6",
"saved": false,
"mod_reason_title": null,
"gilded": 0,
"clicked": false,
"title": "[WTB] 509T yellow spring",
"link_flair_richtext": [],
"subreddit_name_prefixed": "r/GunAccessoriesForSale",
[...]
"contest_mode": false,
"mod_reports": [],
"author_patreon_flair": false,
"author_flair_text_color": "dark",
"permalink": "/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"parent_whitelist_status": null,
"stickied": false,
"url": "https://www.reddit.com/r/GunAccessoriesForSale/comments/1asadbj/wtb_509t_yellow_spring/",
"subreddit_subscribers": 182613,
"created_utc": 1708094934.0,
"num_crossposts": 0,
"media": null,
"is_video": false
}
},
[...]
]
}
}
Jokaisella sosiaalisen median alustalla on omat hienoudet, joita emme valitettavasti voi käsitellä tässä artikkelissa. Jos haluat helposti seurata sosiaalisen median alustoja (kuten Reddit, Linkedin, X, Hacker News ja muut), kannattaa tilata erityinen sosiaalisen kuuntelun alusta, kuten KWatch.io-palvelumme. Kokeile KWatch.io:ta ilmaiseksi täällä.
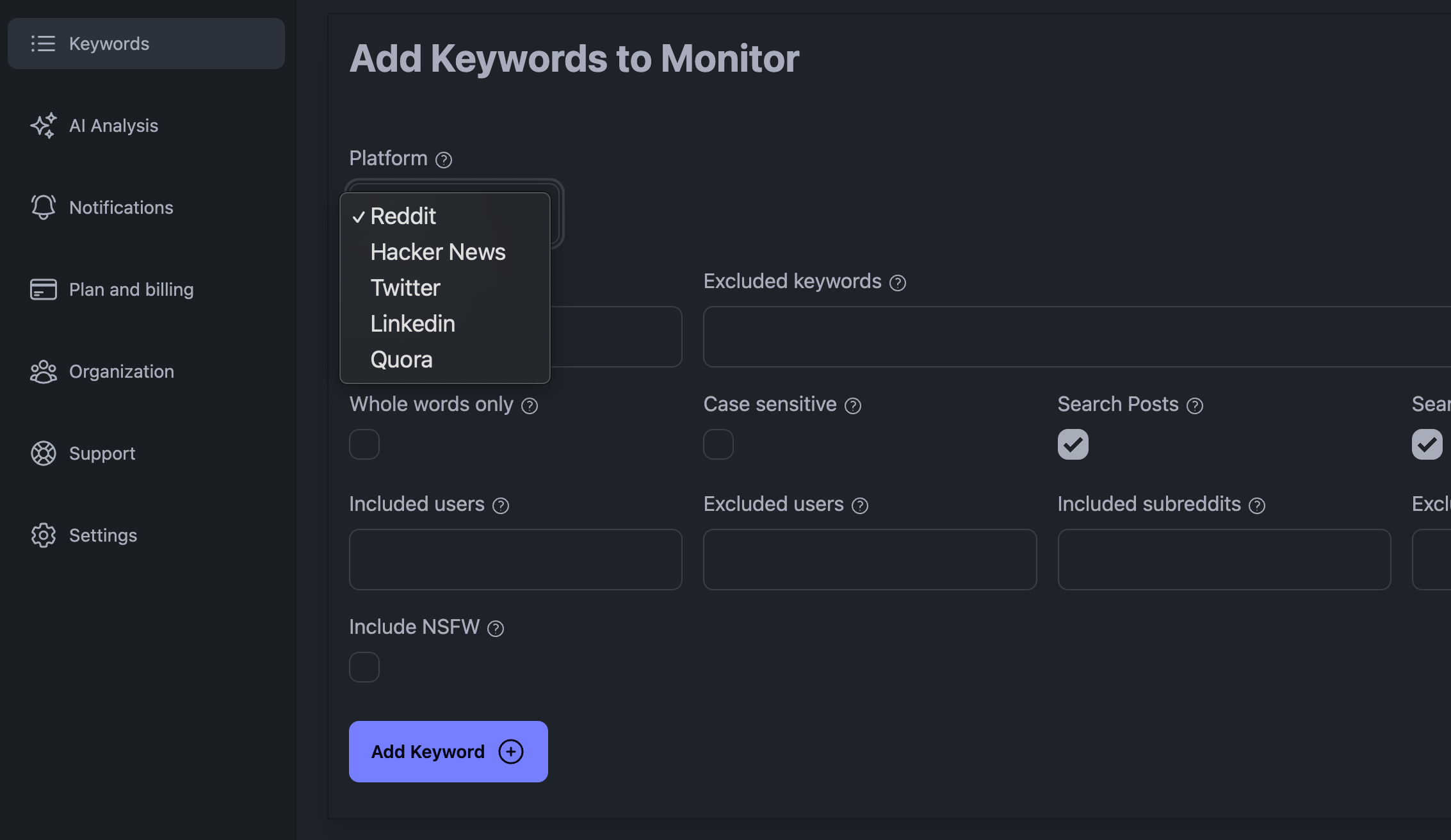
Lisää avainsanoja KWatch.io Dashboardiinsi
Sosiaalisen median kuuntelun tärkeimpiä haasteita ovat käsiteltävien tietojen suuri määrä, se, että sosiaalisen median alustat voivat estää sinua, jos teet liikaa pyyntöjä, ja se, että sinun on oltava fiksu siinä, miten käsittelet tietoja.
Seuraavassa osassa selitetään, miten kerätyt tiedot integroidaan järjestelmääsi.
Sosiaalisen median tietojen integroiminen järjestelmään
Kun olet kerännyt tiedot sosiaalisen median alustoilta, ne on tallennettava tietokantaan tai tietovarastoon. Näin voit analysoida tietoja, tehdä sentimenttianalyysin ja tuottaa oivalluksia.
Sosiaalisen median tietojen (jotka ovat periaatteessa pelkkää tekstidataa) tallentamiseen on useita tapoja, jotka riippuvat vaatimuksistasi ja käsiteltävän datan määrästä. Joitakin yleisiä vaihtoehtoja ovat mm:
- relaatiotietokannan, kuten MySQL:n tai PostgreSQL:n, käyttäminen.
- NoSQL-tietokannan, kuten MongoDB:n tai Cassandran, käyttäminen.
- Käyttämällä tietovarastoa, kuten Amazon Redshift tai Google BigQuery.
Jos olet tilannut sosiaalisen kuuntelun alustan, sinun on tarkistettava, tarjoaako se mahdollisuuden siirtää tiedot järjestelmääsi.
Verkkokoukut, joihin usein viitataan nimellä "web callbacks" tai "HTTP push API", ovat keino, jolla sovellukset voivat jakaa reaaliaikaista tietoa muiden sovellusten kanssa. Tämä saavutetaan luomalla HTTP POST -pyyntöjä, kun tietyt tapahtumat tapahtuvat, ja toimittamalla näin tietoa muille sovelluksille nopeasti.
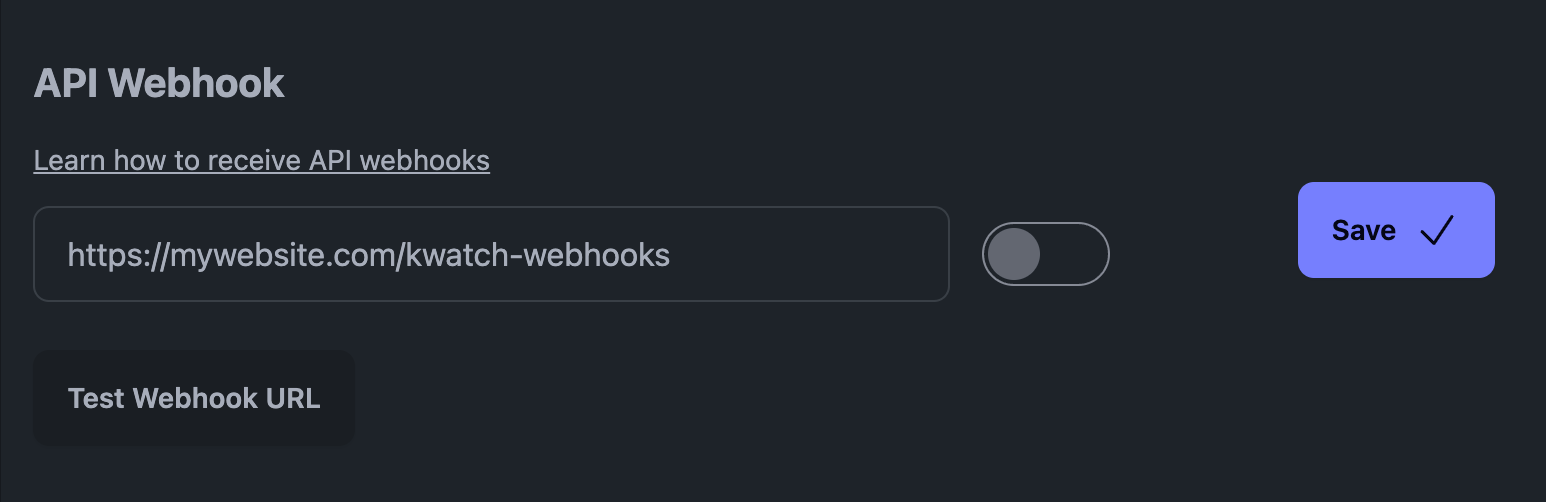
Esimerkiksi meidän alustallamme KWatch.io:ssa sinun pitäisi mennä "ilmoitukset"-osioon ja asettaa järjestelmääsi osoittava webhook-URL-osoite.
API Webhook KWatch.io:ssa
KWatch.io-verkkokoukku näyttää tältä (se on JSON-hyötykuorma):
{
"platform": "reddit",
"query": "Keywords: vllm",
"datetime": "19 Jan 24 05:52 UTC",
"link": "https://www.reddit.com/r/LocalLLaMA/comments/19934kd/sglang_new/kijvtk5/",
"content": "sglang runtime has a different architecture on the higher-level part with vllm.",
}
Jos tämä on sinulle uutta, voit vastaanottaa nämä verkkokoukut vaivattomasti Pythonissa FastAPI:n avulla.
Asenna FastAPI Uvicorn-palvelimen kanssa:
pip install fastapi uvicorn
Luo nyt uusi Python-tiedosto ja liitä seuraava koodi (saatat joutua mukauttamaan tätä skriptiä):
# Import necessary modules
from fastapi import FastAPI
from pydantic import BaseModel
# Initialize your FastAPI app
app = FastAPI()
# Update the Pydantic model to properly type-check and validate the incoming data
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
# Define an endpoint to receive webhook data
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
# Process the incoming data
# For demonstration, we're just printing it
print("Received webhook data:", webhook_data.dict())
# Return a response
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
# Run the server with Uvicorn
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Tallenna tiedosto ja suorita palvelin seuraavalla komennolla:
uvicorn webhook_server:app — reload — host 0.0.0.0 — port 8000
Palvelimesi on nyt käynnissä ja valmis vastaanottamaan verkkokoukkuja KWatch.io:sta.
Tunneanalyysin suorittaminen datasta generatiivisilla tekoälymalleilla, kuten GPT-4 tai LLaMA 3.
Kun olet kerännyt ja tallentanut sosiaalisen median tiedot, voit tehdä niille sentimenttianalyysin.
Nykyään tarkin tapa suorittaa sentimenttianalyysi tiettyä avainsanaa käsittelevälle tekstille on käyttää generatiivisia tekoälymalleja, kuten GPT-4, LLaMA 3, ChatDolphin jne. Nämä LLM-mallit eivät välttämättä ole nopeita ja voivat olla kalliita mittakaavassa, mutta ne takaavat huipputason tulokset. Jos sinun on analysoitava hyvin suuria määriä avainsanoja, voit halutessasi alentaa kustannuksia käyttämällä pienempiä malleja tai hienosäätämällä omaa malliasi.
Voit ottaa käyttöön oman tekoälymallisi tai liittyä tekoälyliittymään, kuten OpenAI:hen tai NLP Cloudiin. Tässä artikkelissa liitämme NLP Cloudin tekoälyliittymän.
Pyyntösi ei tarvitse olla liian monimutkainen. Esimerkiksi tässä on kommentti Redditissä OpenAI:sta:
Kommentti Redditissä OpenAI:sta
Käytetään NLP Cloudin ChatDolphin-mallia analysoimaan OpenAI:ta koskevia tunteita tässä Reddit-kommentissa. Asenna ensin NLP Cloudin Python-asiakasohjelma:
pip install nlpcloud
Nyt voit analysoida Reddit-kommentin tunnetilaa seuraavalla Python-koodilla:
import nlpcloud
brand = "OpenAI"
reddit_comment = "Wasn't it the same with all OpenAI products? Amazing and groundbreaking at first, soon ruined by excessive censorship and outpaced by the competitors"
client = nlpcloud.Client("chatdolphin", "your api token", gpu=True)
print(client.generation(f"What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n{reddit_comment}"))
Vastaus on:
Negative
Lopetetaan nyt ja kirjoitetaan lopullinen koodi, joka kuuntelee API-verkkokoukkua ja suorittaa tunneanalyysin tiedoista:
from fastapi import FastAPI
from pydantic import BaseModel
import nlpcloud
client = nlpcloud.Client("dolphin", "your api token", gpu=True)
app = FastAPI()
class WebhookData(BaseModel):
platform: str
query: str
datetime: str
link: str
content: str
@app.post("/kwatch-webhooks")
async def receive_webhook(webhook_data: WebhookData):
brand = "OpenAI"
print(client.generation(f"""What is the sentiment about {brand} in the following comment? Positive, negative, or neutral? Answer with 1 word only.\n\n
{webhook_data.content}"""))
return {"message": "Webhook data received successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Päätelmä
Kuten huomaat, sosiaalisen median datan sentimenttianalyysi on mahdollista automatisoida nykyaikaisten generatiivisten tekoälymallien ja tehokkaiden sosiaalisen kuuntelun työkalujen avulla. Tätä lähestymistapaa voidaan soveltaa erilaisissa sosiaalisen median seurantatilanteissa. Tässä muutamia ideoita:
- Seuraa brändisi mainetta
- Kilpailijan maineen seuranta
- Osakeoptiota ympäröivän tunnelman seuraaminen
- Tiettyyn teknologiseen suuntaukseen, kuten tekoälyyn tai kryptoon, liittyvien tunnetilojen seuranta.
- ...
Tällaisen ohjelman tuottaminen voi kuitenkin olla haastavaa. Ensinnäkin siksi, että sosiaalista mediaa ei ole niin helppo valvoa, mutta myös siksi, että generatiiviset tekoälymallit voivat olla kalliita käyttää suuriin tietomääriin.
Jos et halua rakentaa ja ylläpitää tällaista järjestelmää itse, suosittelemme käyttämään sen sijaan KWatch.io-alustaa, sillä seuraamme automaattisesti sosiaalista mediaa ja teemme havaituista viesteistä ja kommenteista sentimenttianalyysin: rekisteröityä KWatch.io-sivustolle täällä.
 KWatch.io
KWatch.io